《自然语言处理入门》阅读笔记(1) 第一章+第二章
概述
NLP、计算语言学、自然语言理解(NLU)
自然语言特点:
- 词汇量大,可填充
- 非结构化——信息没有明确的结构关系
- 歧义性
- 容错性高
- 易变性——发展变化快
- 简略性——常识的省略、简称、背景知识
NLP层次:
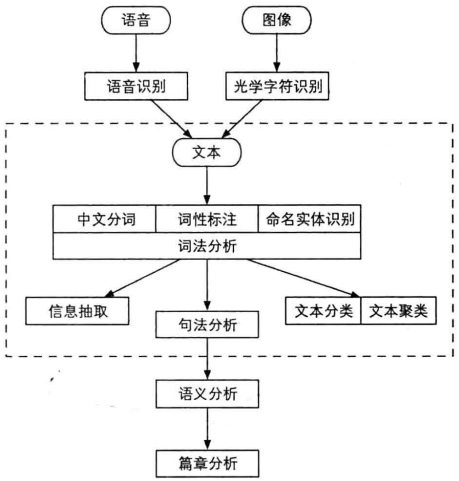
- 词法分析:三个任务,将文本分割为有意义的词语(中文分词)、确定每个词语类别和浅层的消歧(词性标注)、识别专有名词(命名实体识别)
- 文本分类/文本聚类:将相似文本归档、排除重复文档——聚类
- 句法分析:分析句子的主谓宾结构、分析各个词之间的语法信息
- 语义分析、篇章分析:确定一个词在语境中的含义(词义消歧)、标注谓语和其他成分关系(语义角色标注)、分析句子中词语的语义关系(语义依存分析)
流派:基于规则的专家系统、基于统计的学习方法、深度学习
监督学习、无监督学习、半监督学习(训练多个模型预测同一实例,结果多数一致,则将此实例和结果作为新的训练样本,扩充数据集)、强化学习(一边预测,一边根据环境的反馈规划下一次决策)
词典分词
- 中文分词指将一段文本拆分为一系列单词的过程
- 词典分词仅需一部词典和一套查词典的规则即可,重点在于支撑词典的数据结构
词
词:词典中的字符串;词典之外的不是词
齐夫定律:一个单词的词频和它的词频排名成反比
切分算法:将句子切分为一个个词,相当于查词典的规则
完全切分:找出一段文本中所有单词


正向最长匹配:定义单词越长优先级越高,有限输出更长的单词;扫描顺序从前向后
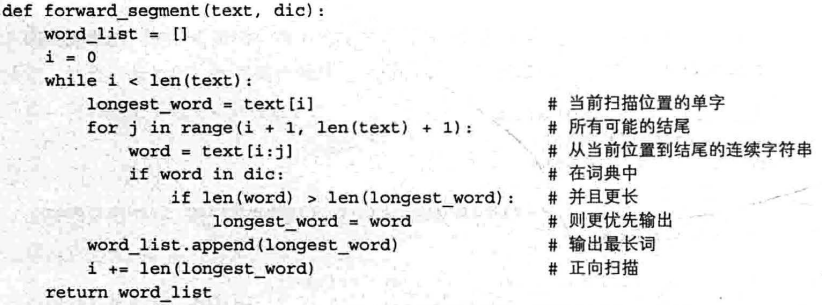

逆向最长匹配:同上,扫描顺序从后向前
双向最长匹配:
- 同时执行正向和逆向匹配,若词数不同,返回次数更少的
- 否则,返回单字更少的
- 否则,返回逆向最长匹配结果
字典树
字符串上的树形数据结构,每条边对应一个字,根节点向下的路径构成一个个字符串——将词语视为根节点到某一结点的路径
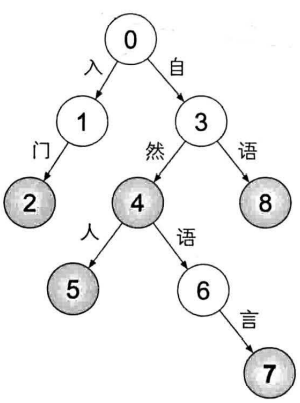
首字散列其余二分:在根节点实施散列
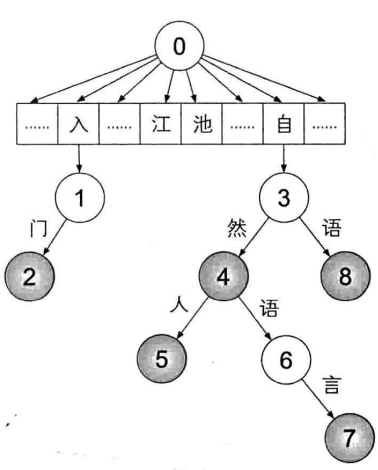
- 利用前缀树状态转移,即,如果扫描“自然语言处理”这句话时,“自然”不在前缀树中,则一切以自然开头的词语都不存在,而朴素的实验会依次查询“自”、“自然”、“自然语”、“自然语言”等词语
双数组字典树
以上字典树,如果存在c个子节点,每次状态转移复杂度都是$O(logc)$,因此提出双数组字典树(状态转移复杂度为常数)
字典树是DFA,双数组字典树也是DFA,DFA中状态由数组base、数组check中的元素和下标表示——状态b接收字符c,转移到状态c,需要满足:

否则状态转移失败

AC自动机
DAT每次状态转移时间复杂度都为常数,但全切分长度为n的文本时,复杂度为$O(n^2)$
AC自动机能一次扫描就查询出所有出现过的单词,时间复杂度为$O(n)$
给定多个词语(也称模式串,pattern),从母文本中匹配的问题称为多模式匹配
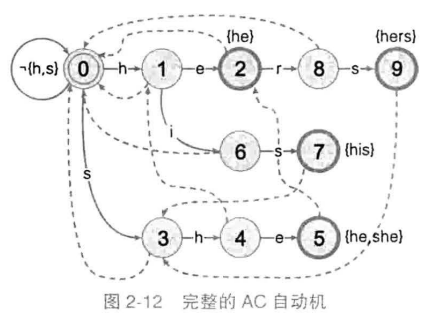
AC自动机在前缀树的基础上,为前缀树上每一个节点建立一个后缀树,以节省查询时间;由goto表、fail表、output表组成
AC算法是一个有向无环图,节点称为“状态”
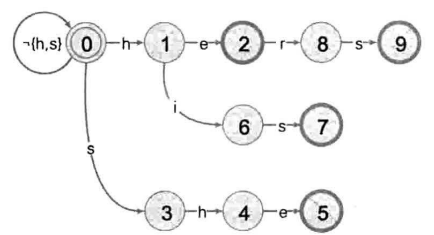
goto表:前缀树,将每个模式串索引到前缀树上
根节点可以根据不同字符转移,也可以接收任意其他字符,转移终点是自己,使得扫描时遇到非目标字符时,状态机一直保持初始状态
下图为识别模式串{he, she, his, hers}的goto表
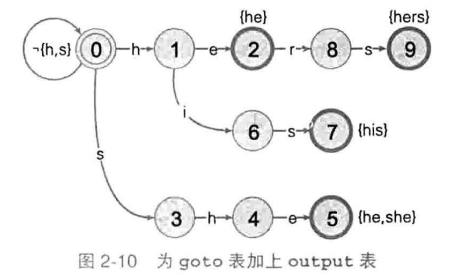
output表:给定一个状态,需要知道该状态是否对应一个或多个模式串——具体实现上可以作为状态对象的一个成员变量
fail表:保存状态一对一的关系,存储状态转移失败后应当回退的最佳状态(能记住以匹配上的字符串的最长后缀)
字典树的状态转移失败时,扫描起点向右挪一位,重新扫描;AC自动机按goto表转移失败时,会按照fail转移,因此只扫描一次文本
下图为完整的AC自动机,fail表用虚线表示
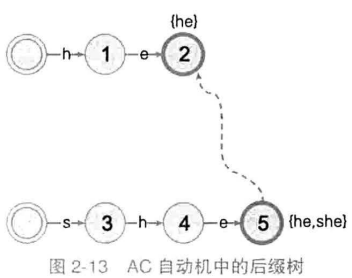
AC自动机由很多后缀树组成,例如:
基于双数组字典树的AC自动机
- goto表本身为一个字典树,可用双数组字典树实现
- ACDAT替换了AC自动机的goto表——goto表本身为字典树,AC自动机只是比字典树多了output表和fail表
- 构建一颗字典树,终止节点记住对应模式串的字典序
- 构建双数组字典树,每个状态映射到双数组时,记住自己在双数组的下标
- 构建AC自动机,此时fail表中存储了状态的下标
中文分词的评估
- 评估标准根据分类问题,可以有精确率P(预测结果中正类数目占所有结果的比例)、召回率R(正类样本被找出的比例)、$F_1$值
- 中文分词是分块问题
- 对长度为n的字符串,分词结果为一串单词,每个单词的起止区间记为$[i,j]$,则标准答案的区间构成集合$A$,此集合外的区间构成负类,分词结果的单词区间构成集合$B$
- 则P、R计算如下($F_1$可根据P、R算出):
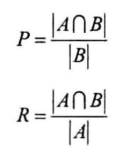
字典树其他应用
- 停用词过滤
- 繁体字、简体字转换
- 拼音转换

