《Leveraging Pre-trained Checkpoints for Sequence Generation Tasks》(BertGeneration)2020 TACL
摘要
- 开发了一个基于Transformer的seq2seq模型,该模型可以使用公开的BERT、GPT-2和RoBERTa的checkpoints,以这些checkpoints初始化本文的模型——编码器和解码器
- 实验表明,本文模型在机器翻译、文本摘要、句子拆分和句子融合方面的实验结果是state-of-art
介绍
很少有人使用预训练模型来初始化seq2seq模型——有人认为BERT的预训练目标导致其不适合用于文本解码任务,但预训练模型在多大程度上有利于seq2seq模型的warmup,这一点尚未由具体研究
本文旨在为以下问题提供一个答案:对于热启动序列生成模型,利用公开的预训练模型的最佳方式是什么?例如,使用BERT的checkpoints初始化编码器,用GPT-2初始化解码器
what is the best way to leverage publicly available pre-trained checkpoints for warm-starting sequence generation models?
本文将BERT、GPT和RoBERTa预先训练的checkpoints结合起来,初始化Transformer模型
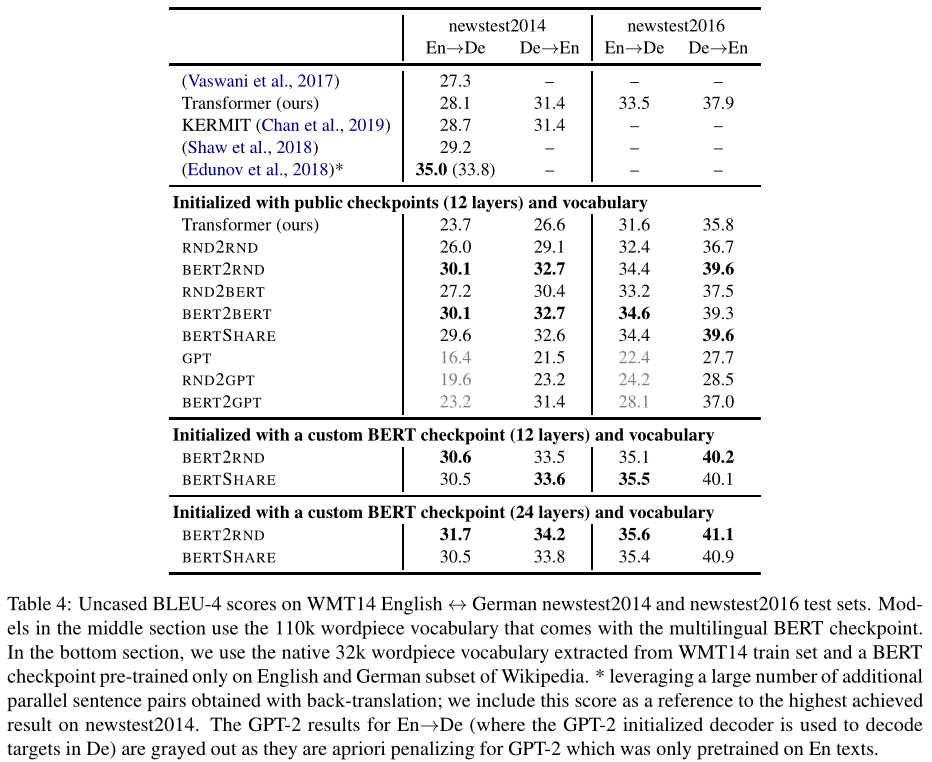
结果表明,预训练的编码器是序列生成任务的重要组成部分,并且序列生成任务通常受益于编码器和解码器之间的权重共享
代码:https://github.com/google-research/google-research/tree/master/bertseq2seq.
模型和checkpoints
BERT是为了NLU任务的文本表示编码而开发的,而GPT-2是为语言建模而开发的
本文使用的seq2seq架构,编码器和解码器都由Transformer层组成
- 编码器使用BERT(这与传统的Transformers不一样,BERT使用GELU激活函数)
- 解码器的实现和BERT的实现相同,但是自注意力机制只会关注左边的上下文(使用了attention mask把右边的文本掩盖住),并且添加了编码器-解码器注意力机制

BERT Checkpoints:
- 使用WordPiece分词
- 使用bert-base-uncased、bert-base-cased、BERT-Base Multilingual Cased作为checkpoints
GPT-2 Checkpoints
- 使用SentencePieces分词
- GPT-2有1024个位置的位置嵌入,但仅使用前512个(为了和BERT匹配起来)
Roberta Checkpoints
词汇的处理和GPT-2的句子分词兼容
As the conceptual differences between BERT and RoBERTa are minor, we might use BERT as a hypernym to address both pretraining methods in this paper.
模型组合
- RND2RND:Transformer的encoder-decoder架构,但权重均随机初始化
- BERT2RND:BERT初始化的编码器与随机初始化的解码器配对。编码器和解码器共享从checkpoint初始化的嵌入矩阵
- RND2BERT:随机初始化的编码器与BERT初始化的解码器配对。为了实现自回归解码,将BERT的双向自注意机制屏蔽为只看左边的上下文
- BERT2BERT:BERT初始化解码器和BERT初始化编码器配对;唯一随机初始化的变量是编-解码器的注意力
- BERTSHARE:类似于BERT2BERT,但编码器和解码器之间的参数是共享的
- ROBERTASHARE:与BERTSHARE相同,但是共享编码器和解码器使用公共Roberta的checkpoints初始化
- GPT:纯解码器架构。将输入视为语言模型的条件前缀
- RND2GPT:随机初始化的编码器与GPT-2解码器配对。用GPT-2的checkpoints来预热解码器和嵌入矩阵
- BERT2GPT:使用BERT的字典作为输入,使用GPT-2的字典作为输出
- ROBERTA2GPT:类似BERT2GPT,但用RoBERTa来初始化编码器
实验和结果
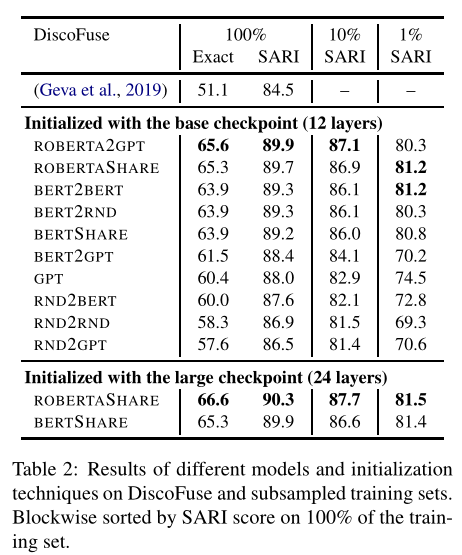
句子融合:将多个句子组合成一个连贯的句子
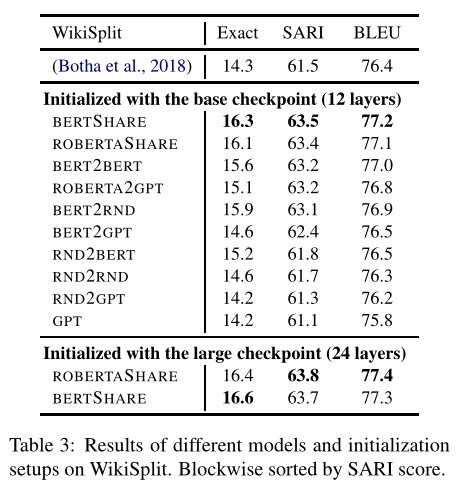
句子拆分:与句子融合任务相反,需要将一个句子拆分为多个句子来表达
机器翻译