《Cross-lingual Language Model Pretraining》(XLM)2019 NIPS
摘要
- 本文将生成式预训练扩展到多种语言,提出训练跨语言的语言模型(XLM)的两种方法
- 只依赖单语言数据的无监督方法
- 使用并行数据和新的跨语言语言模型训练目标的有监督方法
- XLM在跨语言分类、无监督和有监督机器翻译方面取得了最先进的结果
介绍
- 本文证明了跨语言模型预训练,在多个跨语言理解(XLU)的benchmark上有显著提升
- 贡献:
- 引入一种新的无监督方法,用于学习跨语言的representation
- 引入一种新的有监督训练目标,在并行数据可用的情况下提高了跨语言预训练的效果
- 跨语言模型可以显著改进低资源语言的复杂性
相关工作
- 本文工作基于BERT、GPT
跨语言模型
本文提出了三个训练目标,前两个只需要单语数据(用于无监督训练),第三个需要并行语料(用于有监督训练)
考虑$N$个语种语料,记为$C_i$($i=1,..,N$),语料$C_i$有$n_i$个句子
共享sub-word字典
构建包含各个语言使用词语的多语词表(既然是多语模型,这个模型要能够接收各个语言的句子作为输入)
同样使用BPE,但不是把各个语言的BPE词表拼接起来,而是先对各个语料分别采样,然后将各个语言的采样语料拼接,最后进行正常的BPE处理——采样的目的是将大语种的语料和小语种的语料进行平滑,以免小语种都被按照字符拆分了
通过一个多项式分布对句子采样,采样概率$q_i$($i=1,…,N$)如下,$\alpha$为0.5:
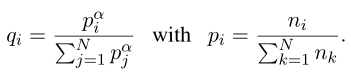
训练目标:CLM
- causal language modeling任务由一个Transformer语言模型组成,用于在给定前面单词的情况下给出下一个单词的概率$P(w_t|w_1…w_{t-1},\theta)$
训练目标:MLM
掩码语言任务,也称为完形填空任务
类似BERT的预训练,从文本流中随机抽取15%的BPE token,其中的80%用[MASK] token替换,10%用随机的token替换,10%保持不变
与BERT预训练不同的是,BERT的输入使用成对的句子,而本文使用由任意数量的句子(每个句子截断为256个token)组成的文本流代替成对的句子——即,将物理上相邻的多个句子当作一整个句子组,选择两个句子组作为输入对
为了均衡稀有tokens和高频tokens(比如标点符号和stop words),本文采用类似于2013年Mikolov等人在《Distributed representations of words and phrases and their compositionality》提出的方法,对高频词汇进行二次采样:文本流中的tokens都是以多项式分布进行采样的,其权重与它们的文本频率倒数的平方根成正比
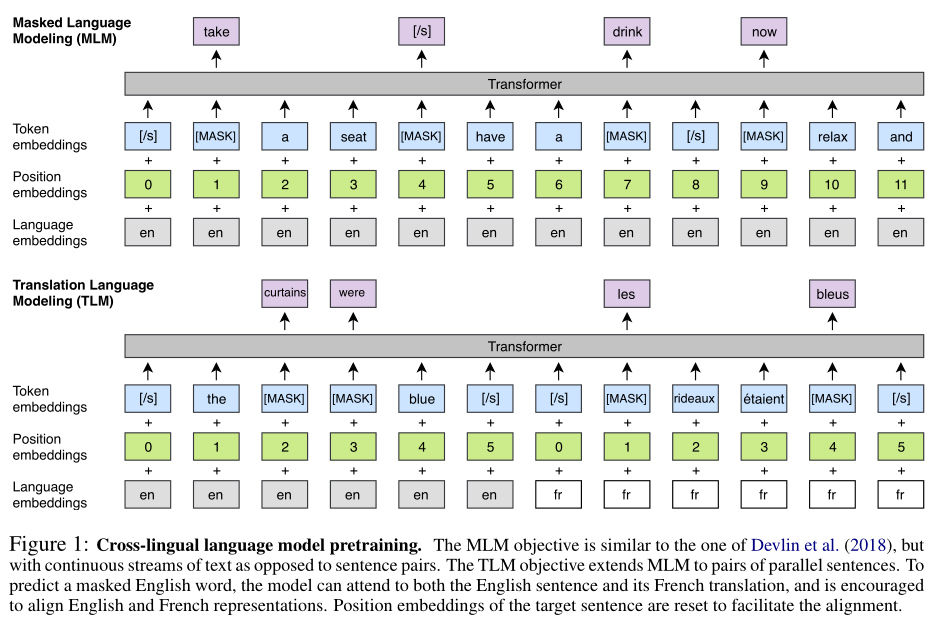
训练目标:TLM
- CLM和MLM都是无监督的,只需要单语数据——当存在平行语料数据时,两者都无法使用
- 本文提出一种新的翻译语言建模方法(TLM)来提高跨语言训练的效果
- TLM是MLM的扩展,不考虑单语种的文本流, 而是将并行的翻译句子拼接起来。如上图所示,在source句和target句中都随机mask一些tokens,此时要预测英文句子中被mask的token时,模型不仅能够注意到英文token,还能够注意到法语的翻译内容,因此能引导模型将英语和法语的representation进行对齐;特别地,该模型在source句不足以推断出被mask的token时,能够利用target句的上下文信息
- 为了方便对齐,在target句部分,位置编码需要重置
跨语言模型(XLM)
- 考虑三种训练方式:
- 只使用CLM
- 只使用MLM
- MLM和TLM联合使用
- 前两种,batch size为64,句子长度为256个token;每个iteration,一个batch由同一个语言的句子组成,并且通过前面的分布采样得到,此时的$\alpha$为0.7
- 第三种,MLM和TLM交替训练,使用类似的方法采样输入的句子对
实验
跨语言分类
XLM模型提供了通用的跨语言的文本表征
在预训练模型上添加一个线性分类器
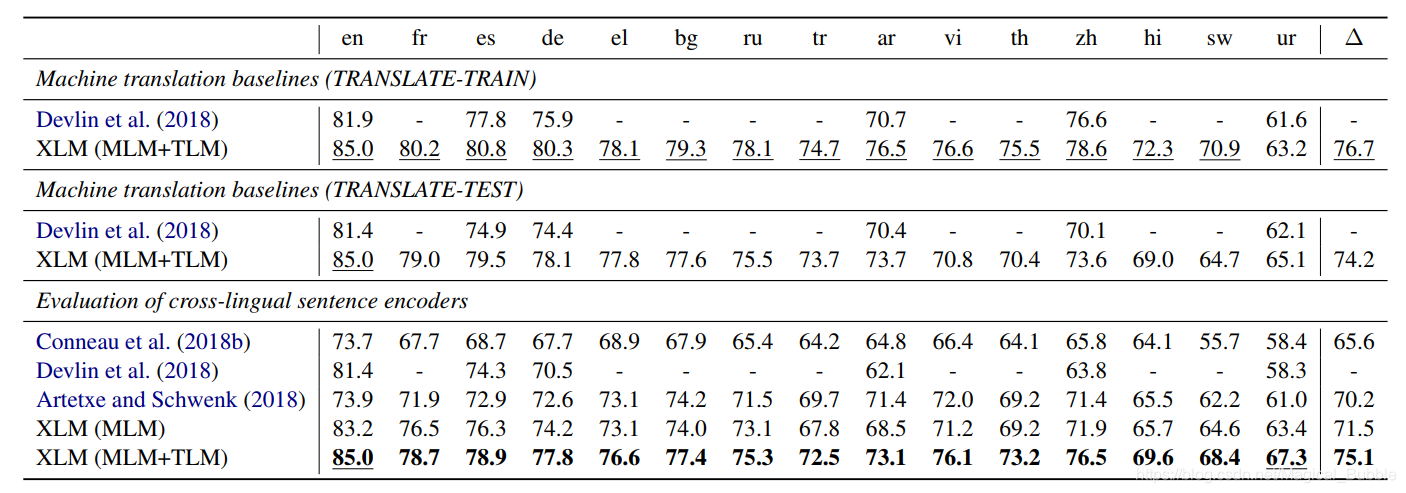
在跨语言分类benchmark上微调XLM,并使用XNLI来评估
- XNLI的训练集都是英文的,验证集是多语种的
- XNLI本质上还是文本蕴含任务
实验结果:
无监督机器翻译
大致含义为,给出两个语言语料(不要求平行),应当能学会翻译——类似人类在学会中文和英文之后,就应当能够进行翻译,此时两个语言之间的连接关系是语义,而不是词表的对应
无监督机器翻译在不考虑预训练的情况下,大多使用去噪自编码器+循环翻译
- 去噪自编码器:以英文的去噪自编码器为例,搭建一个encoder-decoder模型后,英文语料加入噪音输入encoder,decoder输出原始的英文语料——目的在于让encoder 学习语义信息
- 循环翻译:以英译中为例,就是先让英文文本加上噪音,经过encoder-decoder,得到翻译的中文伪数据,然后将中文伪数据再次送入encoder-decoder,得到原来的英文数据
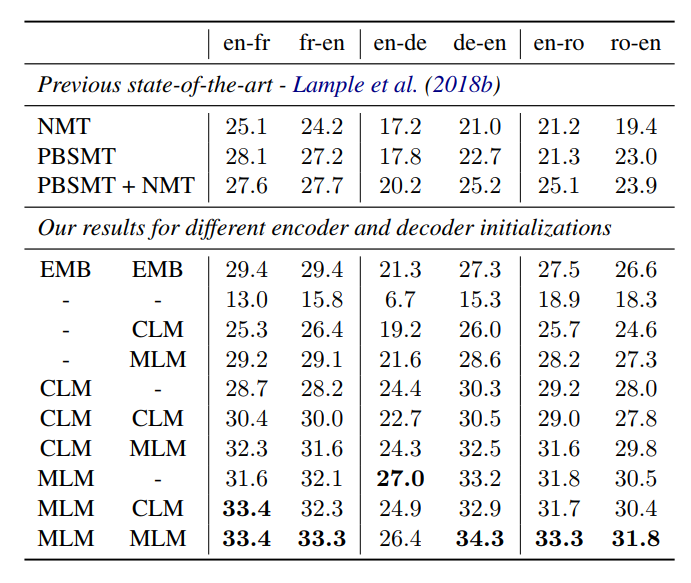
探索了多个初始化策略,评估各种策略在机器翻译任务上的表现
在本文中,用CLM、MLM或者随机初始化的方式,初始化encoder和decoder,下表展示了不同初始化方法的结果
有监督的机器翻译
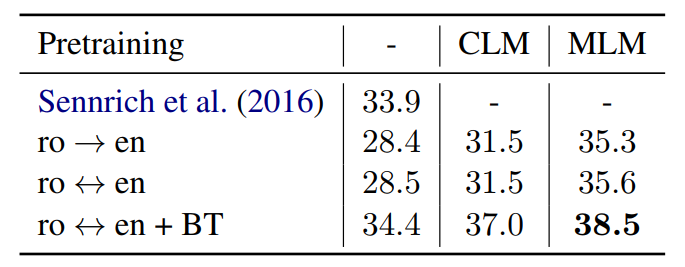
第二行:用单向数据进行fine-tune
第三行:用双向数据进行fine-tune
第四行:用双向数据fine-tune,但同时进行back-translation(即A->B先生成伪数据,再翻译回A)
具体的训练过程?
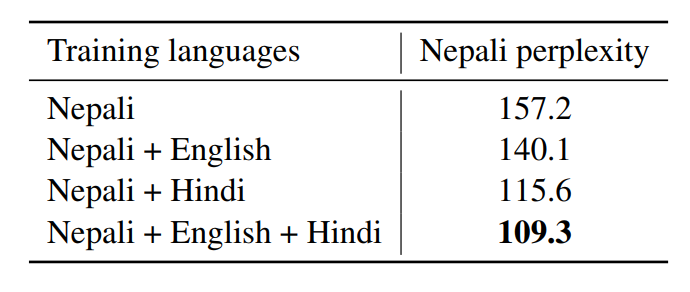
冷门语言的建模
- 验证多语训练对小语种语言模型建模的影响
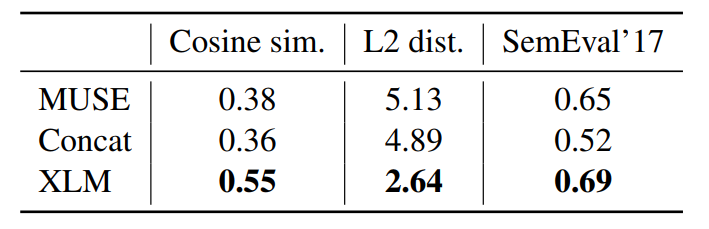
无监督跨语言词嵌入
验证无监督情况下,生成的跨语言embedding的优秀程度
验证各种源单词,和其翻译词之间的距离,包括三种:余弦相似度、L2距离和跨语言词语相似度
总结
本文首次验证预训练跨语言模型(XLM)带来的收益
- CLM和MLM作为预训练目标,都可以提供很好的跨语言功能,可以用于预训练模型
- 无需使用任何的平行句语料,跨语言模型在XNLI跨语言分类任务上的平均准确率,超过最优的有监督模型1.3个百分点
- TLM使用平行语料提升了跨语言模型的预训练。TLM天然地扩展了BERT的MLM方法,在MLM上使用TLM能够进一步提升结果指标,以高出平均准确率4.9%的优势刷新了此前XNLI的记录

