《A General Framework forGuided Neural Abstractive Summarization》(GSum)2021 NAACL
摘要
- 本文提出一个通用的、可扩展的引导式摘要框架(Guided summarization framework)——不同类型的外部引导(guidance)作为输入
- 使用突出显示的句子作为指导,根据ROUGE在四个摘要数据集上实现state-of-art性能
- 本模型可以生成更加可信的摘要,展示了不同类型的引导如何生成质量不同的摘要,从而为模型的训练提供一定的可控性
介绍
文本摘要的生成方法包括:
- 提取(extractive)——从输入文档中识别最合适的单词或句子,连接起来(2018NAACL:《Ranking sentences for extractive summarization with reinforcement learning》、2018ACL:《Neural document summarization by jointly learning to score and select sentences》)
- 生成(abstractive)——自由生成,能够产生新颖的单词和句子,更加灵活,更容易产生流畅的摘要(2018ICLR:《A deep reinforced model for abstractive summarization.》)
- 容易生成不忠实(unfaithful)的摘要,包含事实错误和虚假内容
- 难以控制摘要的内容,很难事先判断模型会学习原始文本的哪些方面
本文提出引导性生成式摘要,提供各种类型的引导信号。引导信号可以约束摘要,使得输出内容和原始文档偏差更小,并通过用户指定输入提供一定的可控性
过去也有类似的方法,但过去的方法都侧重于一种特定类型的引导,如摘要的长度、关键字等,但不清楚哪一种更好,是否能相互补充
本文模型基于encoder-decoder,用预训练语言模型——BERT、BART——初始化,以此为起点训练
对模型做了修改,使得模型在生成输出时关注源文档和指导信号
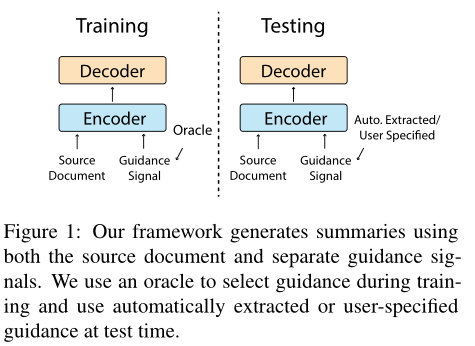
在测试期间可以为模型提供自动提取的,或用户指定的指导,以约束模型输出
在训练期间,为了使模型给指导信号分配注意力,本文使用一个oracle来选择指导信号,指导信号包括:
- 源文档中的高亮句子
- 关键词
- 以(主语、关系、宾语)形式出现的具有显著关系的三元组
- 检索到的摘要
用6个数据集做评估,本文模型在使用高亮句子作为指导时,在其中的4个数据集实现最先进的性能
证明不同的指导信号之间是相互补充的,因此有可能将它们的输出汇总起来,获得更好的效果
背景和相关工作
生成式摘要(或者,抽象式摘要)
- 通常以源文档$\mathbb{x}$作为输入,源文档由句子$x_1,…,x_{\mathbb{|x|}}$组成
- 输入encoder获得文档的表征,再输入decoder,一次生成一个单词的摘要
- 模型参数$\theta$要最大化并行语料库$(X,Y)$的输出条件似然性:$argmax_\theta\sum_{\mathbb{(x^i,y^i)}\in(X,Y)}logp(\mathbb{y^i|x^i};\theta)$
- 相关技术:
- 复制模型(将一个单词复制到输出):2018EMNLP:《Bottom-up abstractive summarization》
- 覆盖模型(防止生成重复的文字):2017ACL:《Get to the point: Summarization with pointer-generator networks》
指导
- 除了源文档外的输入到模型的信号$\mathbb{g}$,此时最大化目标为:$argmax_\theta\sum_{\mathbb{(x^i,y^i,g^i)}\in(X,Y,G)}logp(\mathbb{y^i|x^i,g^i};\theta)$
- 相关方法:
- 先生成一组关键词,然后通过注意力机制将其结合到生成过程中
- 搜索训练语料,检索与当前输入最相关的文档,将其作为候选模板来指导摘要生成
- 从源文档提取主语、关系、宾语的三元组,以图神经网络表示,decoder之后处理提取的关系,来生成摘要
- 使用saliency model来提取关键词或者高亮句子,送入摘要模型
方法
下图为本文的通用框架
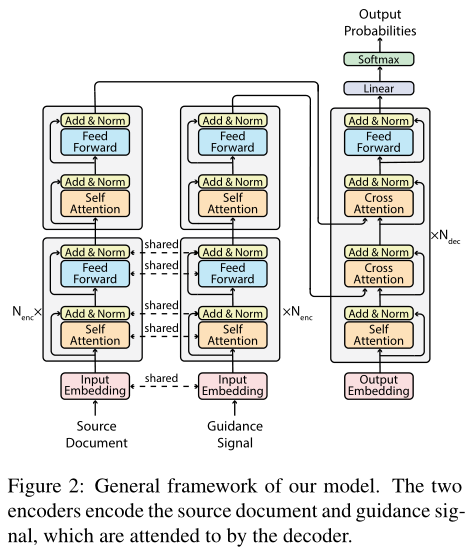
模型结构
用Transformer作为主干模型,使用BERT或BART实例化
encoder
- 两个编码器,分别编码源文档和指导信号
- 每个编码层包含一个自注意力块和前馈块
- 编码器共享底部的$N_{enc}$层、嵌入层参数
decoder
decoder必须同时处理源文档和指导信号
decoder每层包含四个块:
自注意力块后,decoder关注指导信号并生成相应的表征(指导信号告知解码器应当关注源文档的哪部分),decoder将基于指导信号的表征关注整个源文档,最后输出送入前馈块
过程如下:

理想情况下,第二个交叉注意力块应当允许模型填充引导信号的细节,例如通过搜索共同的co-reference chain来找到实体名
指导信号的选择
- 测试时,可以通过人工方式来定义指导信号,或者通过automatic prediction来从源文档推断指导信号
- 训练时(此时样本多,人工方式成本高),通过以下两种方式获取,用于训练:
- automatic prediction:基于源文本的输入信息,自动预测指导信息$G$(类似抽取式的方法)
- oracle extraction:通过联合文本的输入信息和标准摘要信息来生成$G$(即,用摘要和源文本来训练模型,以明白源文本哪个词或句子更关键)
- 高亮句:
- oracle:使用贪婪搜索算法(《Summarunner: A recurrent neural network based sequence model for extractive summarization of documents》、《Text summarization with pretrained encoders》),在源文档中寻找一组ROUGE分数最高的句子,作为指导信息
- automatic:使用预训练的摘要抽取模型BertExt(2019)或MatchSum(2020)来自动获取关键句
- 关键词:
- 关键句中仍然可能存在无关信息,因此使用来自源文档的关键词
- oracle:先通过上面的贪婪搜索算法选择关键句,再通过TextRank来抽取关键词
- automatic:使用BertAbs来获得源文档对应摘要中的关键词
- 关系三元组
- 关系可以用关系三元组表示——奥巴马出生在夏威夷,转化为(奥巴马,出生在,夏威夷)
- oracle:使用StandFord OpenIE来提取关系三元组,然后使用贪婪搜索算法选择一组与参考具有最高ROUGE分数的关系,将其展平(flatten)作为参考
- automatic:使用一个类似于BertAbs的模型来获得关系三元组
- 检索到的摘要:
- 输入相似文档的摘要可以作为源文档摘要的参考
- oracle:通过Elastic Search,从训练数据中检索5个与目标摘要$\mathbb{y}$具有相似摘要的数据样本$((\mathbb{x_1,y_1},…,(\mathbb{x_5,y_5}))$
- oracle:检索5个源文档与输入源文档最相似的数据点
实验
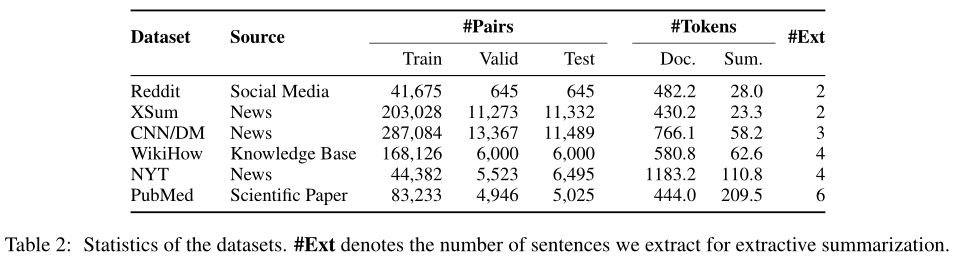
数据集
选择六个数据集:
Baseline
- BertExt
- BertAbs
- MatchSum
- BART
执行细节
- 基于BertAbs和BART分别构建本文的模型,使用它们的超参数训练
- BertAbs:13层encoder,顶层随机初始化
- BART:24层encoder,顶层用预训练参数初始化
- decoder的第一个交叉关注块随机初始化,第二个交叉关注块使用预训练参数初始化
- 训练时使用oracle extractions
主要结果
这里的BertAbs(Ours)是指什么?自己用相同模型训练后的测试结果?
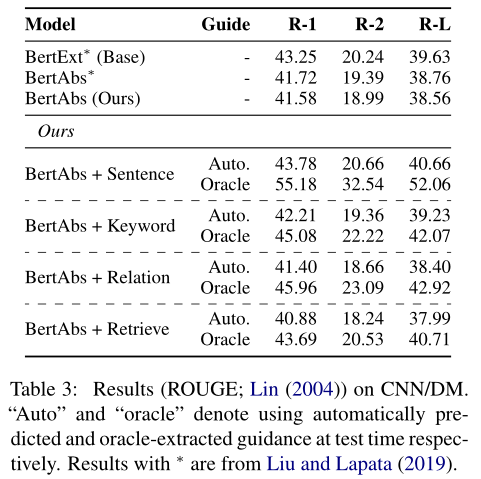
CNN/DM上使用BertAbs比较不同类型的指导信号
- 如果指导信号更加准确,则模型性能有进一步提高的可能
- 模型确实学会了关注指导信号
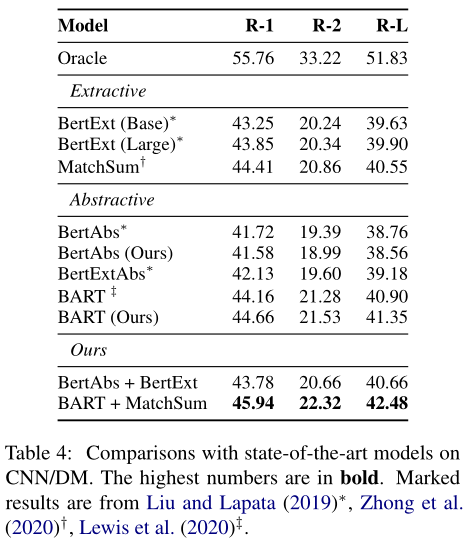
CNN/DM上本文最佳结果,对比其他论文方法
- 用BART建立模型,用oracle方法获取的高亮句作为指导信号训练
- 使用MatchSum来获得测试时的指导信号
其他五个数据集上使用BertAbs和BART评估最佳的指导信号(oracle获取高亮句)