《Unsupervised Cross-lingual Representation Learning at Scale》(XLM-R)2020 ACL
介绍
提出XLM-R,一种基于transformer的多语言掩码语言模型。XLM-R在100种语言的文本上预训练,性能显著优于mBERT(即BERT,但用了多语种的语料训练),在跨语言分类(cross-lingual classification)、序列标注和问答任务上是state-of-art的
跨语言理解领域的早期工作已经证明了多语言掩码语言模型(multilingual masked language models)在跨语言理解方面的有效性,但是诸如XLM和multilingual BERT这样的模型(都在Wikipedia上预训练)在学习低资源语言的有用表示方面仍然能力有限
本文实验结果表明,在固定模型参数下:在一定程度上,更多的语言可以提高低资源语言的跨语言性能,但超过该临界点后,单语言和跨语言的benchmark上的性能将下降——本文称此为“多语言诅咒”(curse of multilinguality)——而简单地增大模型,可以有效缓解多语言诅咒
相比于XLM和mBERT,XLM-R的改进:
在XLM和RoBERTa中使用的跨语言方法基础上,XLM-R增加语种数量和训练数据集规模
调整模型的参数——在词汇构建过程中对低资源语言进行上采样,以生成更大的共享词汇表,并将模型增加到5.5亿个参数
方法
- 尽可能遵循XLM的方法,只引入以下几个变化
MLM
- 模型主体还是Transformer,训练目标是多语种的MLM,基本和XLM相同,从每个语种的语料中采样出文本,再预测出被mask的tokens
- 语料采样方案和XLM相同,只是设置$\alpha=0.3$
- 文本不使用Language Embeddings
- 文本词典的大小为250k
- 训练两个模型,$XLM-R_{Base}$和$XLM-R$——这里的R表示RoBerta
扩大语料库
在100种语言上训练
增加数据集规模(下图为维基百科语料库和本文使用的CommonCrawl语料库规模对比)
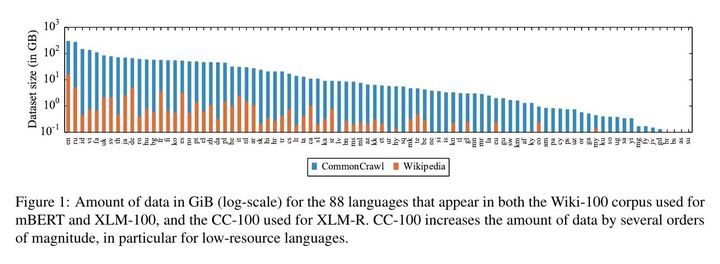
实验中发现,几百MiB的文本数据通常是学习BERT模型的最小规模
评估
四个benchmark:跨语言的自然语言理解、命名实体识别和问答,以及GLUE来评估XLM-R的单语言性能(英语)
跨语言分类
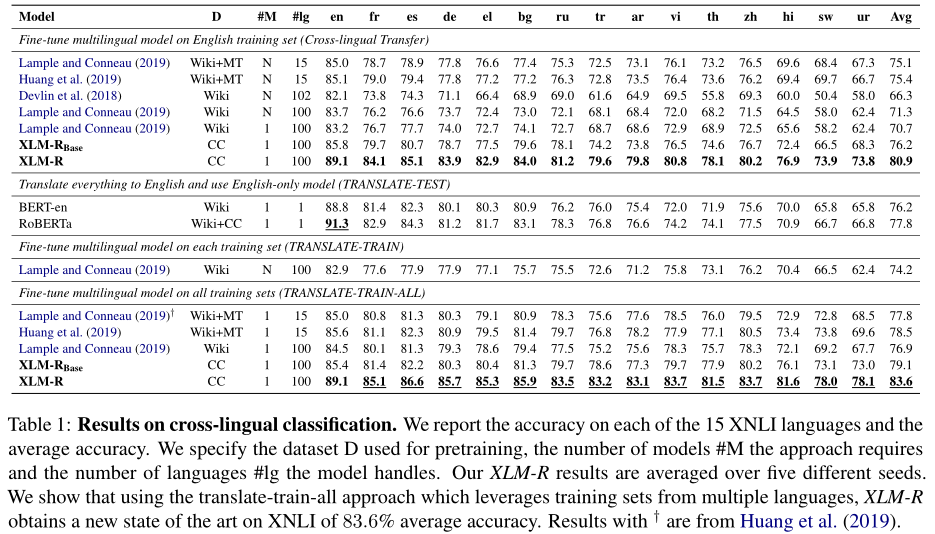
XNLI上实验,D列表明用于预训练的数据,#Ig表示语种数目
命名实体识别
略
问答
略
与BERT在单语言任务上的对比
比单语种BERT效果好,但没有用100个语种预训练的XLM-R,而是用XLM-R做对比,同时没有和RoBERTa对比,而是和BERT对比

