《Masked Sequence to Sequence Pre-training for Language Generation》(MASS)2019 ICML
本文发表时间在XLM之后(本文认为,基于XLM的seq2seq模型,其中的encoder和decoder是分开进行预训练的,都是XLM,因此encoder到decoder之间的注意力无法被预训练)
摘要
- 受BERT的启发,提出MASS,用于语言生成任务
- MASS采用encoder-decoder框架,在给定句子某一部分情况下,恢复其余部分
- encoder以具有随机屏蔽片段的句子作为输入
- decoder预测该屏蔽片段
- 通过进一步微调,在NMT、文本摘要和会话响应任务上,相比baseline有显著提高
介绍
BERT不适合做语言生成任务,因为BERT是为语言理解任务设计的,此类任务大多只需要一个encoder或decoder
MASS基于seq2seq框架,encoder以带有mask片段(多个连续的token被mask)的句子作为输入,解码器基于encoder的表征预测这些片段
通过预测句子中的mask片段,MASS强迫encoder理解未mask的token
decoder的输入需要将句子没有被mask的片段mask掉,从而decoder将会更多地依赖encoder输出的表征
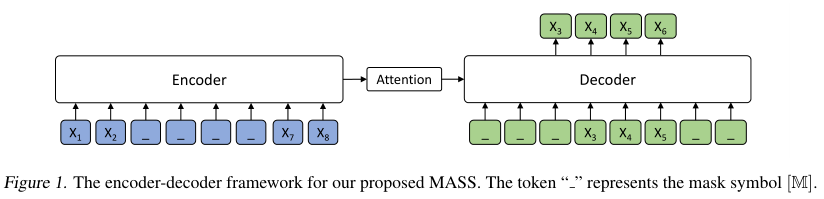
以Transformer为基本的seq2seq模型进行预训练
本文贡献:
- 提出MASS
- 将MASS应用于各种语言生成任务,以证明本文方法的有效性
MASS
记$(x,y)\in(X,Y)$是一对句子,其中$x=(x_1,…,x_m)$是源句,$y=(y_1,…,y_n)$是目标句,分别由m和n个token组成
seq2seq模型学习参数$\theta$以估计条件概率$P(y|x;\theta)=\prod_{t=1}^nP(y_t|y_{<t},x;\theta)$,并且通常使用对数似然作为目标函数
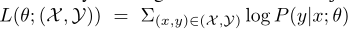
seq2seq预训练
- 将$x$中位置$u$到位置$v$的token遮掩,得到新的源句$x^{/u:v}$,并且被遮掩的token数目记为$k$,被遮盖的部分记为$x^{u:v}$
- MASS以$x^{/u:v}$为输入,预测$x^{u:v}$,训练目标为:
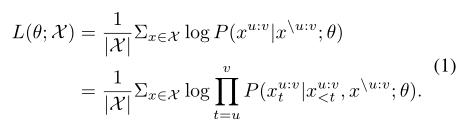
- 当$k=1$,等价于BERT;当$k=m$,表明这个句子都被mask,等价于GPT(此时decoder需要再给定先前token的情况下,预测所有的token)

由于只预测被mask的tokens,encoder被迫理解句子没有被mask的部分的含义,并鼓励decoder从encoder提取有用的信息;通过在decoder侧预测连续的tokens,提高了decoder的建模能力(比只预测一个token要好);通过进一步屏蔽在encoder侧没有被屏蔽的decoder侧输入token,例如当预测内容为$x_3x_4x_5x_6$时,只将$x_3x_4x_5$作为decoder的输入,其他token被mask,估计decoder从encoder提取更多的信息,而不是偏向于利用前面tokens的信息
By further masking the input tokens of the decoder which are not masked in the encoder side, the decoder is encouraged to extract more useful information from the encoder side, rather than leveraging the abundant information from the previous tokens.
这里decoder的输入到底该如何设定?究竟哪些要预测的内容不被遮盖?
实验
预训练
- transformer作为基本结构,嵌入层和hiddensize为1024,encoder和decoder各6层
- encdoer中被mask的token,80%时间为[mask],10%时间为原始token,10%时间为随机的token
- decoder中降低内存和计算成本的方法:
- 移除decoder中被mask的token,但保留其位置嵌入
- 例如,前两个token被mask,则舍弃前两个token,输入直接就是$x_3…$,但$x_3$对应的位置嵌入为2而不是0
- 使用Adam优化器,学习率为$10^{-4}$
- 基于XLM代码实现本文方法
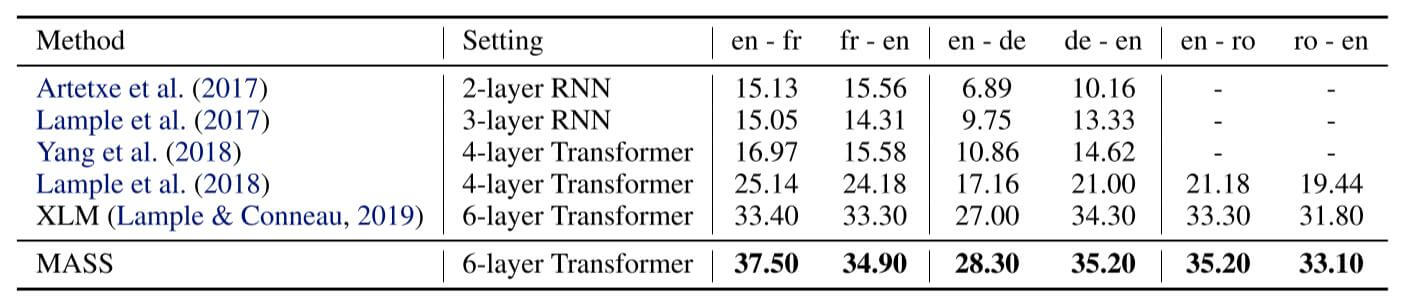
机器翻译
无监督的机器翻译上BLEU得分如下
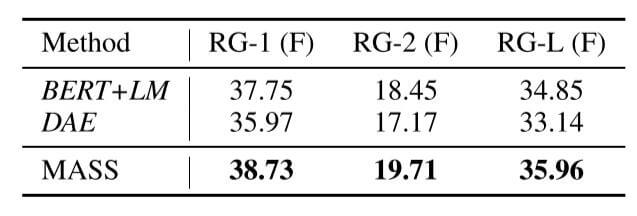
文本摘要
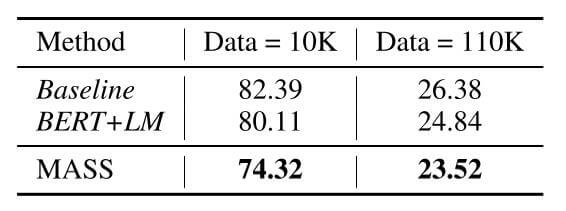
对话生成
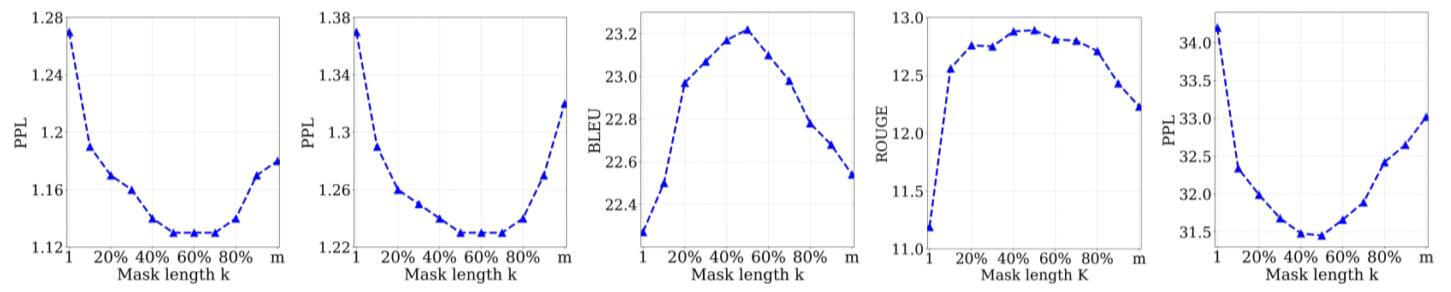
k值分析
- 所有任务几乎都在$k=0.5*m$时效果最好
总结
- MASS与BART属于相同类型的模型——将BERT用到Seq2Seq框架下做生成任务
- MASS更侧重decoder的改进, BART更侧重对加噪方法的调整

