《In Search of an Understandable Consensus Algorithm》(raft,2014)
摘要
- Raft是一个管理replicated log的一致性算法
- 和Paxos算法的运行结果相同,但更加可理解
- Raft分离了共识的关键元素,如领导者选举、日志复制
- 包括一个改变集群成员的新机制,使用overlapping majority来保证安全
介绍
- 共识算法使得一组机器能以一个连贯的集体工作,大多数共识的实现都基于Paxos
- Raft分离了领导者选举、日志复制和安全模块,缩减了状态空间——减少不确定的程度,以及服务器之间发生不一致问题的情况
- Raft的特征
- Stronger leader:日志条目只能从领导者流向其他服务器,简化了复制日志管理
- Leader election:使用随机计时器选举leader
- Membership changes:改变集群中服务器集合的时候,大多数两种不同的配置会在过渡期间重合,使得集群在配置更改期间继续运行 > the majorities of two different configurations overlap during transitions
复制状态机
- 共识算法通常出现在复制状态机的环境中
- 复制状态机用于解决分布式系统中各种容错问题,使用独立的复制状态机来管理leader election,并存储能够在领导者挂掉后恢复的配置信息
- 通常使用复制日志实现复制状态机:服务器存储包含系列命令的日志,状态机按顺序执行相同的命令——由于状态机是确定性的,给定相同的状态和输入,最终一定会得到一致的状态和输出
- 一致性算法需要保证复制日志的一致性,其特点为:
- 确保安全性(不返回错误结果),即使网络延迟、分区、数据包丢失、数据包重复或数据包乱序
- 只要大多数服务器运行并可以相互通信,则一定可用——例如,五个服务器的集群能够在两个服务器故障下仍然提供服务
- 不依赖时间来保证日志的一致
- 只要集群里大多服务器响应了一轮RPC,就可以完成一个命令
Paxos的问题
- Paxos首先定义一个能在单个决策上达成共识的协议,然后组合该协议的多个实例以促进一些系列的决策
- Paxos的问题:
- Paxos解释性不好——Paxos的不透明性来自其选择一个子集作为基础,没有直观的解释
- 实际实现存在困难——没有广泛认可的multi-Paxos算法
- 实际系统和Paxos几乎没有相似之处
- 本文将问题分解:只要有可能,就将问题分成可以相对独立解决、解释的的部分
- 本文通过减少要考虑的状态数来简化状态空间,例如限制日志变得不一样的方式,消除了一定不确定性;引入随机化的方法,通过相似的方式来处理所有可能的选择,从而减少了状态空间——use randomization to simplify the Raft leader election algorithm
Raft一致性算法

- raft选举一个领导者,让领导者完全负责复制日志的管理:接受客户机的日志条目,并复制到其他服务器,告诉服务器何时应用日志条目
- 基于领导者,Raft将共识问题分解为三个子问题
- 领导者选举(当领导者挂掉,需要选择新的领导者)
- 日志复制
- 安全:如果任何一个服务器将一个特定的日志条目应用到它的状态,则其他服务器不能对同一个日志条目,应用不同的命令
Raft基础
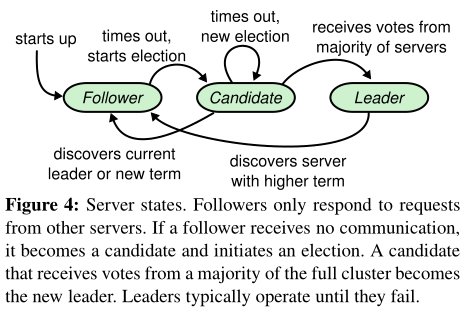
Raft集群包含多个服务器,服务器将充当leader、follower、candidate
一般的,只有一个leader,其他均为follower
follower不主动发出请求,只回应leader和candidate
leader处理所有客户端请求(若客户端联系follower,follower将重定向到leader)
candidate用于选举新的leader
Raft将时间分为任意长度的项(term),用连续的整数编号,每个term都以选举leader开始(在多个candidate中),如果发生分裂投票(split vote),则term会结束,新的term将马上开始
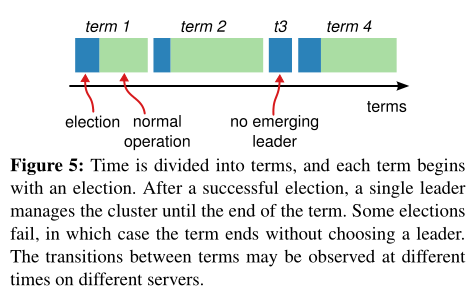
term使得服务器检测到过时的信号——服务器都会存储term编号,并且在通信时先交换、更新各自的term为最大值
- 如果candidate或leader发现自己的term较小,则回到follower状态
- 服务器会忽略带有过期term的请求
Raft使用RPC进行通信,基本的一致性算法只需要两种RPC:RequectVote RPC和AppendEntries RPC
- RequectVote RPC由candidate在选举期间发起
- AppendEntries RPC由领导者发起,以复制日志和检查其他服务器存活状态(心跳检测)
- 可能会有第三个RPC,用于服务器间传递快照
- 若没有及时收到响应,则会重试RPC
Leader选举
- Raft使用心跳机制触发leader选举——leader定期向followers发送心跳(无日志条目的AppendEntries RPC),若follower在一个选举超时的时间内没有收到信息,则开始选举新的leader
- 发起选举的follower的操作:
- 增加当前term,过渡为candidate状态
- 为自己投票,并行地向集群中其他服务器发出RequestVote RPC
- candidate持续此状态,直到:
- 成为leader
- 要求该candidate从大多数服务器获得选票
- 给定期限里,服务器按先到先得原则为至多一个candidate投票
- 向其他服务器发送心跳
- 另一个服务器成为leader
- 要求新leader的term至少等于candidate的term,candidate转为follower
- 否则拒绝该RPC,仍未candidate
- 没有人成为leader
- 选票可能被分割,没有人获得大多数选票
- 每个candidate都会超时,各自的term增加,开启新一轮的RequestVote RPC
- 如果没有额外措施,分裂投票可能会一直重复
- 成为leader
- Raft使用随机选举暂停(randomized election timeouts)确保分裂投票很少发生——选举超时的时间,从固定的时间间隔里随机选择
Log复制
每个客户端请求都包含一个复制状态机要执行的命令,leader将该命令作为新条目添加到日志,并行地向follower发送AppendEntries RPC以复制该条目
条目复制后,leader将条目应用到状态机并把结果发回给客户机,若follower崩溃或网络数据丢失,则leader无限期充实AppendEntries,即使已经响应客户端,直到所有follower存储所有日志条目
日志格式如图:
条目存储一个状态机命令以及条目被leader收到时的term号
term用于检测日志的不一致
每个日志条目都有一个整数索引,以便于在所有日志中检索它
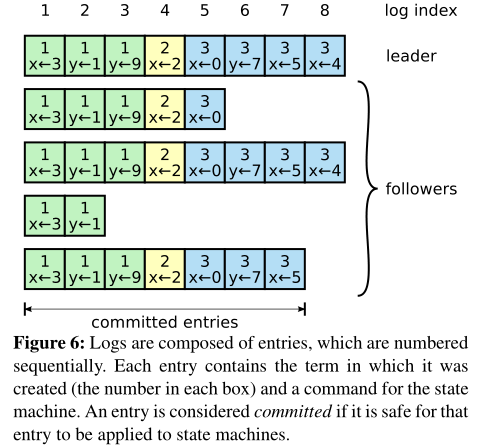
leader决定日志条目应用到状态机的时间,以保证安全——此时该条目称为committed,Raft保证committed的条目会被所有可用的状态机执行
- 一个log会被commit,如果该log在大多数服务器上被复制
- 一旦follower得知日志条目被commit,follower就将该条目应用到其本地状态机(按日志顺序)
Raft维护日志匹配属性:
- 如果不同日志中的两个条目有相同的索引和term,则存储相同的命令
- 如果不同日志中的两个条目具有相同的索引和term,则其前面的条目都相同
每当日志被扩展时,都会检查日志匹配属性
leader挂掉可能会导致旧的leader没能完全复制它的所有条目,此时发生不一致问题,例如:
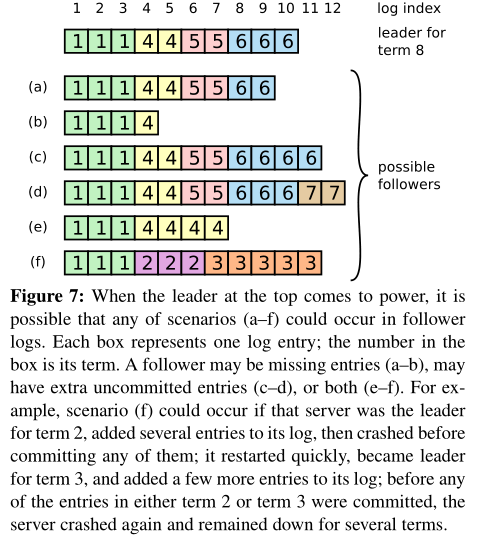 * leader强迫follower复制自己的日志,以处理日志的不一致——即,冲突的条目会被leader的条目覆盖,leader要找到最新的一致条目,然后删除follower之后的条目,并把leader在该点之后的条目发过去
* 此过程在响应AppendEntries RPC执行的一致性检查中进行
* leader为每个follower维护next index,即下一个日志条目的索引
* When a leader first comes to power, it initializes all nextIndexvalues to the index just after the last one in its log.
* leader强迫follower复制自己的日志,以处理日志的不一致——即,冲突的条目会被leader的条目覆盖,leader要找到最新的一致条目,然后删除follower之后的条目,并把leader在该点之后的条目发过去
* 此过程在响应AppendEntries RPC执行的一致性检查中进行
* leader为每个follower维护next index,即下一个日志条目的索引
* When a leader first comes to power, it initializes all nextIndexvalues to the index just after the last one in its log.
leader从不覆盖或删除自己日志中的条目
Safety
- 添加对哪些服务器可以被选为领导者的限制,完善Raft算法
选举限制
leader必须最终存储所有commit的日志条目
Raft保证从每个新leader当选的时刻起,过去的term中commit的条目就存在于其身上——日志条目只从leader流动到follower
Raft使用voting来防止不包含所有commit条目的candidate赢得选举,candidate必须获得集群中的大多数投票才能称为leader
RequestVote RPC包含有关candidate日志的信息,如果投票人的日志比candidate的日志更fresh,投票人将拒绝给他投票——通过比较日志中最后条目的索引和term来确定新鲜程度(先看term,再看索引)
从过去的term来commit条目
- 不通过计算副本从过去的term来commit 条目,而是对副本计数,仅仅commit leader当前term的日志条目
- 当leader从以前的term中复制条目时,日志条目会保留它们的原始term编号
Safety argument
论证leader完整性性质成立——基于安全性证明(略)
Follower和candidate挂掉
- Raft无限重试来处理follower和candidate挂掉的问题
- 如果崩溃的服务器重新启动,RPC将成功完成
- 如果服务器完成RPC,但在响应前崩溃,它在重新启动会再次收到相同的RPC
- 如果follower收到的AppendEntries RPC包含其日志中已经存在的条目,则会忽略
时间和可用性
- 安全性不能依赖于时间:系统不能因为某个事件的发生得比预期快/慢产生错误的结果
- 要求:
broadcastTime << electionTimeout << MTBF以保证选出leader- broadcastTime为服务器向集群中其他服务器并行发送RPC,并收到响应的平均时间
- electionTimeout为选举超时时间
- MTBF为单台服务器的平均故障间隔时间
- 第一个和第三个时间为底层系统的属性,选举超时一般在10ms到500ms
集群成员变更
- 以上都在假设集群中服务器固定
- 自动化配置更改,并合并到Raft共识算法,保证过渡期间不会有两个leader在同一个term当选
- 配置更改使用两个阶段:
- 首先集群切换到一个过渡配置(称为joint consensus)
- 一旦提交了联合共识,则系统转换到新的配置
- 联合共识结合了新的和旧的配置
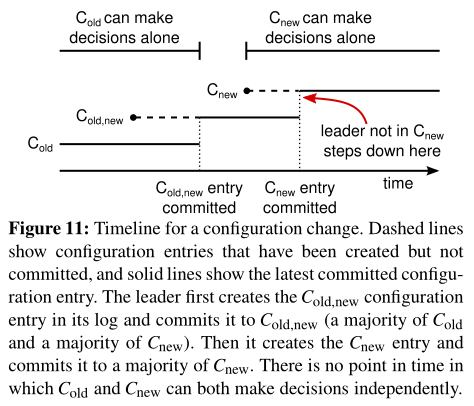
- 使用复制日志中的特殊条目来存储和传递集群配置
- 上图显示了配置更改过程
- 图中$C_{old}$为旧的配置,$C_{new}$为新的配置
- $C_{old,new}$为联合共识的配置

