《How to Attack and Generate Honeywords》(2022 S&P)
摘要
- Honeyword是与每个用户帐户相关联的诱饵密码,用于及时检测密码泄露,但关键问题在于如何生成与真实密码相近的Honeyword
- 现有的研究主要是以特定的方式处理Honeyword
- 首先提出四个理论模型描述攻击者A的最佳区分策略,每个模型都基于A可用信息的不同组合(例如,公共数据集、受害者的个人信息和注册顺序)
- 四种最佳攻击理论的支持下,通过使用各种有代表性的概率密码猜测模型,为每种类型的攻击者开发了相应的Honeyword生成方法,实验和用户研究结果表明,本文方法明显优于现有技术
- 设法解决了在蜜语方法的实际部署中出现的几个以前未探索的挑战
介绍
- 基于密码的认证系统中,服务器需要维护一个保存所有用户密码的文件,该文件是攻击者的攻击目标,一旦该文件被攻击者以某种方式获得,用户的密码就会被离线猜测
- 用户需要在被告知密码泄露时更改他们的密码,但是如果没有及时的检测机制,相应的响应对策是不可能的
- Juels和Rivest在CCS’13首次提出了Honeywords,用于实现及时的密码漏洞检测。Honeywords为每个用户帐户生成诱饵密码,与用户的真实密码一起存储。真实密码的索引存储在另一个服务器中(称为honeychecker),攻击者必须区分真正的密码与同一组的k-1个Honeywords,用Honeywords登录表示密码文件泄露
- 关键问题在于,如何生成一组无法与真实密码区分的Honeywords。Honeywords生成方法分为两类:
- 基于遗留用户界面(UI)的方法
- 用户方面没有变化
- 基于修改的UI的方法
- 用户需要改变行为
- 本文主要关注基于遗留用户界面的Honeywords生成方法
- 基于遗留用户界面(UI)的方法
Design challenge
- 13年的文章将基于遗留UI的方法分为两类:chaffing-by-tweaking and chaffing-with-a-password-model。但是,密码模型的使用看似简单,但实际上相当具有挑战性
- 不太可能使用一个密码模型来生成与用户密码具有相同概率的Honeyword
- 用户密码服从Zipf的分布,因此不可能生成足够多得到候选Honeyword,使得与真实密码具有相同概率,因此攻击者可以使用概率模型来区分Honeyword和真实密码
- 每种密码模型都有其弱点,PCFG低估了交错密码的概率(例如密码1A2B3C4D),Markov模型低估了较长但具有实际意义的密码,因此使用单个密码模型来生成蜜语是不合适的
- 攻击者是强大的,因此需要假设攻击者知道服务器使用哪种密码模型生成Honeyword,同时攻击者还可以知道用户的私人信息(PI)
- 用户的注册顺序是有意义的(从用户第一次发言时间,和用户注册号码可以获知此信息)
- 不太可能使用一个密码模型来生成与用户密码具有相同概率的Honeyword
相关工作
- 略
本文贡献
- 攻击理论:首次提出了一系列基于攻击者各种能力的理论模型(利用受害者的个人信息、知道用户注册顺序等)
- 生成方法。基于各种现有的概率密码破解模型(markov、PCFG、TarGuess PCFG)开发四种Honeyword生成方法,解决Juels-Rivest的问题,给出一种新的利用破解模型构建Honeywords的方法,使得破解模型的未来改进能够兼容Honeywords
- 深入的评估。在四种攻击者下进行大量实验来展示生成Honeyword方法的有效性。实验建立在11个大规模数据集上,并对11名人类攻击者进行用户研究
- 一些见解。攻击理论表明,chaffing-by-tweaking的方法本质上是有问题的,这样的方法都不是平坦的(可区分的),而自适应列表模型(不是预期的PCFG或Markov)可以在只有公共数据集的攻击者的情况下生成几乎扁平的蜜语
前置知识(Preliminaries)
系统模型
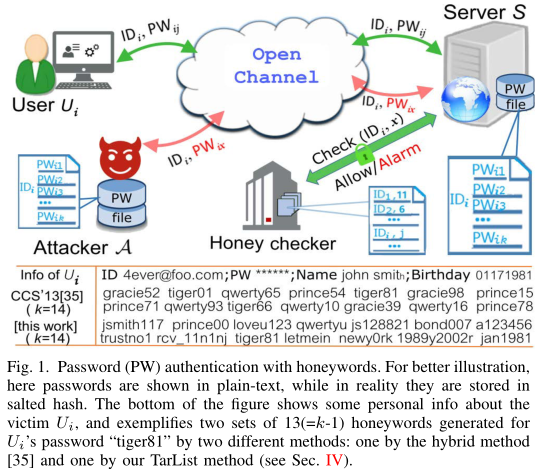
Honeyword系统包含四个部分:一个用户$U_i$,一个验证服务器$S$,一个honeychecker,攻击者$A$
用户首先在$S$创建一个账号$(ID_i,PW_i)$,一些PII可能会提供给$S$,$S$还提供命令$Gen(k;PW_i)$以生成k-1个Honeyword,和真实密码一起存储
基于随机替换的Honeyword生成方法(Honeyword和真实密码明确相关)和基于密码模型的Honeyword生成方法(Honeyword和真实密码独立)
Juels的第一个方法“Tweaking by tail”作为非密码模型的方法的代表,真实密码的最后几位被相同类型的字符替换(数字被数字替换,字母被字母替换)
安全模型
Honeyword distinguishing attacker
- 如果攻击者使用$T_1$个Honeyword登录,则服务器发出警告给用户
- 如果攻击者使用$T_2$个Honeyword登录,则服务器发送系统范围的警告
- 需要平衡Honeyword攻击和Dos攻击,$T_2$不能太小或者太大,一般为$10^4$
Attacker capabilities

- $A_1$为基本的攻击者
- 一些用户喜欢用自己的PII构建密码
- 用户的注册顺序同样是有意义的i虚拟西
Other attackers
- 针对Honeyword的其他攻击还包括多系统交叉攻击(multi-system intersection attacks)、DoS攻击、honeychecker攻击
- 多系统交叉攻击通常源于用户在多个网站重用密码,可以通过好的加密来抵御
- DoS攻击(故意用Honeyword登录以引起系统的暂停服务)——生成阶段生成更加flat的Honeyword,服务器在认证阶段采用适当的措施,例如速率限制和Captcha schemes,并基于强Honeyword更大的决策权重
衡量方法
- 衡量一个honeyword方法的goodness
- Flatness graph:
- the chance y of finding the real password by making x login attempts per user, x <= $T_1$
- 衡量average-case表现
- Success-number graph:
- the number y of successfully identified real passwords, when the attacker has made a total of x honeyword login attempts, x <= $T_2$
- 衡量worst-case表现
概率密码模型
不考虑神经网络
PCFG
Markov
List:$P_D(s)=\frac{Count(s)}{|D|}$
TarPCFG:称为TarGuess-I,除了LDS之外,还定义了一些新的基于PII的tag。TarPCFG在100次猜测内的表现比PCFG高412%-740%
TarMarkov:只需要将PII的tag加入到Markov的alphabet,所有的操作都和atomic character类似
TarList:List模型本质上可以看作一个没有LDS的PCFG,因此转换过程也就类似了
Honeyword的生成:
- 对于概率密码模型,从概率空间中采样即可生成Honeyword
- 对List模型,直接从中采样
- 以PCFG为例:
- 首先从模板中采样,得到基本结构$L_7D_3$
- 之后从对应字符串采样得到wanglei和123
- 对于混合的模型,首先决定选择哪一个密码模型,然后再采样生成
- 对于targeted model,类似地获得包含PII tag的模板,用用户的PII替代相关标签。例如,可能会先生成$N_2123$,然后将$N_2$(family name)替换为用户的family name
数据集
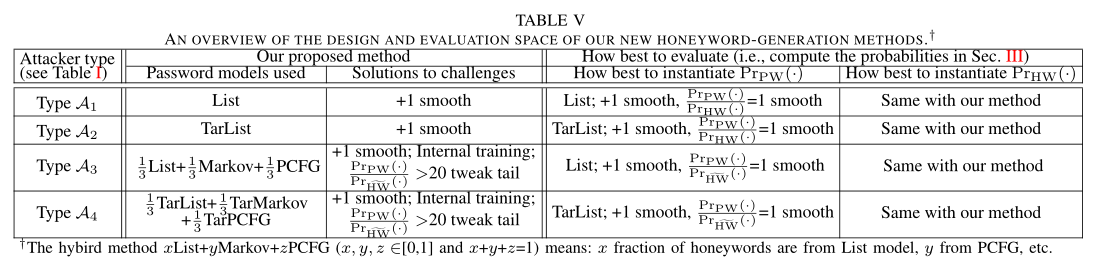
本文的攻击理论
理论攻击模型
全局目标:从给定的密码列表$F$中识别真实密码(n组sweetword,每组包含k-1个honeyword和1个真实密码)
局部目标:给定一个用户的sweetword,识别出真实密码
本节公式、理论很多,略过
结果
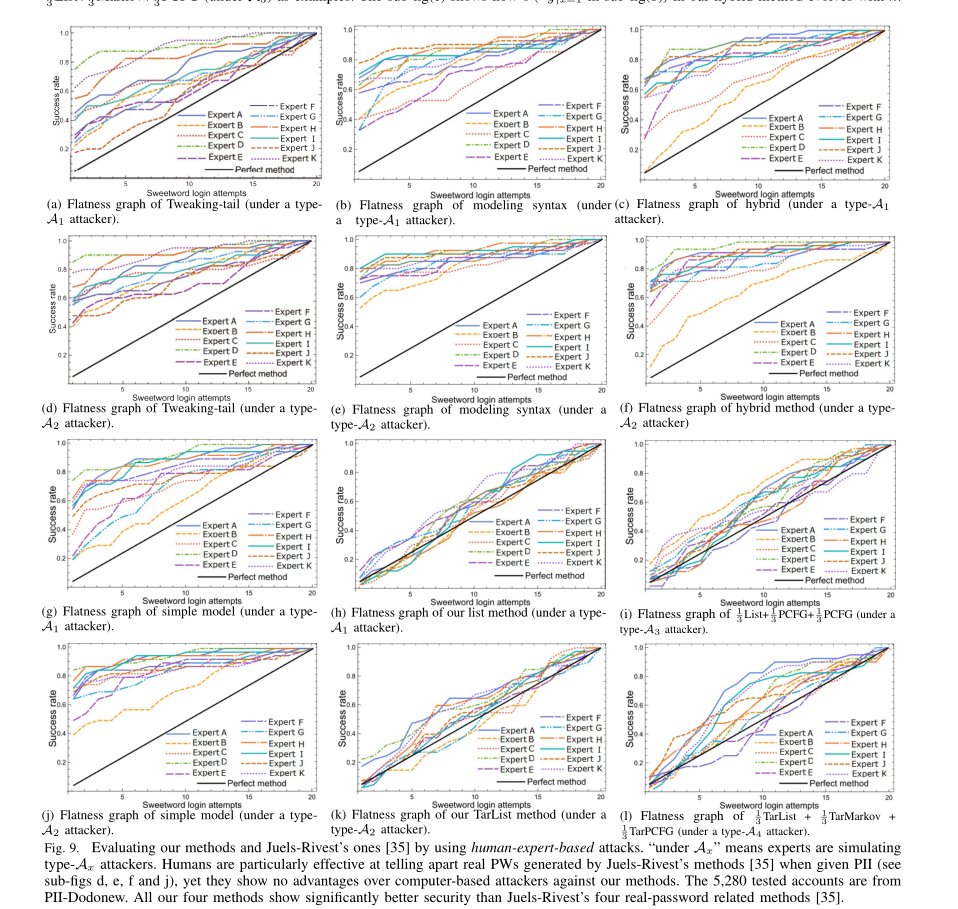
遗留问题:攻击者采用了什么方式生成攻击密码?这个暂时没有读到

