《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》(2021)
摘要
- 传统的监督学习方法对给定的x训练一个模型,预测对应的y($P(y|x)$)
- prompt-based learning基于语言模型直接对文本的概率进行建模,具体为:输入x中加入一个模板(template),其中含有需要预测的位置slots,语言模型预测slots中应该出现的词的概率,填充为$\hat x$——y可以从中学到
- prompt-based learning优势:
- 在大量的原始文本中预训练
- 设计一个prompt函数,使模型可以作用于小样本(few-shot)或者零样本(zero-shot)
- 自适应到其他场景的少量或者没有标签的数据
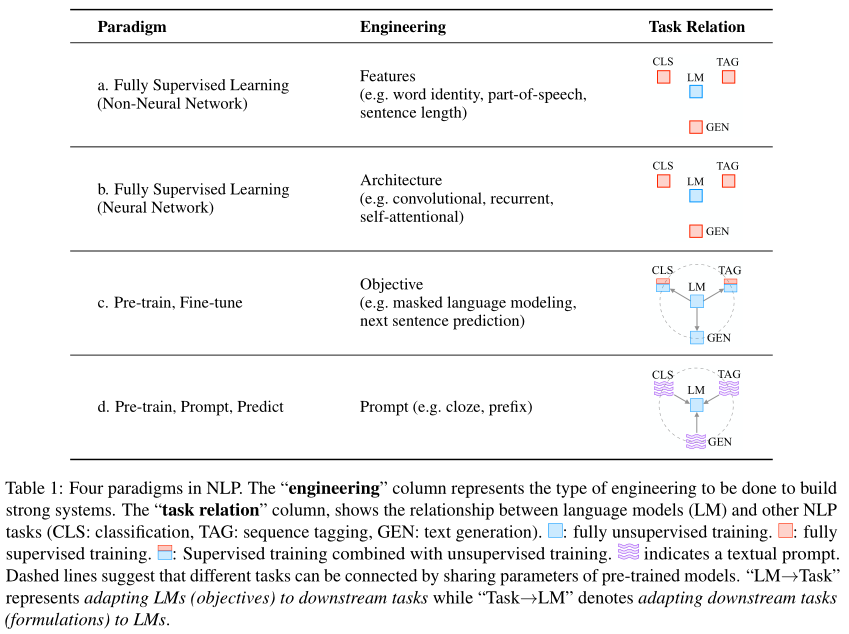
NLP的两次重大变化
早期NLP模型严重依赖于特征工程
中期转向architecture engineering:设计有助于学习特征的合适网络架构
2017-2019,完全转变方向:从完全监督范式转为预训练+微调范式,需要设计objective engineering,即设计在预训练和微调阶段使用的训练目标
2021,又有一次巨变,pretrain+finetune可能被pretrain+prompt+predict替代
- 不再通过目标工程(objective engineering)使得预训练模型适应下游任务,重新定制下游任务,借助textual prompt(文本提示)使其看起来像是原始训练期间解决的任务
- 例如,在文本情感分类的下游任务,给定“I miss the bus”,可以加一个提示“I felt so [mask]“,以此要求LM用一个带有情感的词填充
- 选择适当的提示,可以操纵模型行为,使预训练的模型本身用于具体任务
由此,完全无监督的方式训练的单个LM可以解决大量的任务,但问题在于如何选择合适的prompt
Section2:提供prompt方法的概述和形式化定义
Section3:概述使用prompt的预训练模型
Section4:prompt engineering
Section5:answer engineering
Section6:multi-prompt learning methods
Section7:prompt-aware training methods
Section8:基于prompt学习方法的应用,以及如何利用prompt method
Section9:与其他研究领域的联系
Section10:挑战性的问题
A Formal Description of Prompting
NLP监督学习
- 给定输入x,基于模型$P(y|x;\theta)$预测输出y
- 数据集为x y的数据对
Prompting Basics
- 监督学习需要大量监督数据
- Prompt-based learning通过建模$P(x;\theta)$并使用该概率预测y
- 三个步骤如下
Prompt Addition
- 使用一个prompt函数$f_{prompt}(\cdot)$将输入文本x转为提示$x’=f_{prompt}(x)$
- 大多数以往工作里,函数包含两步:
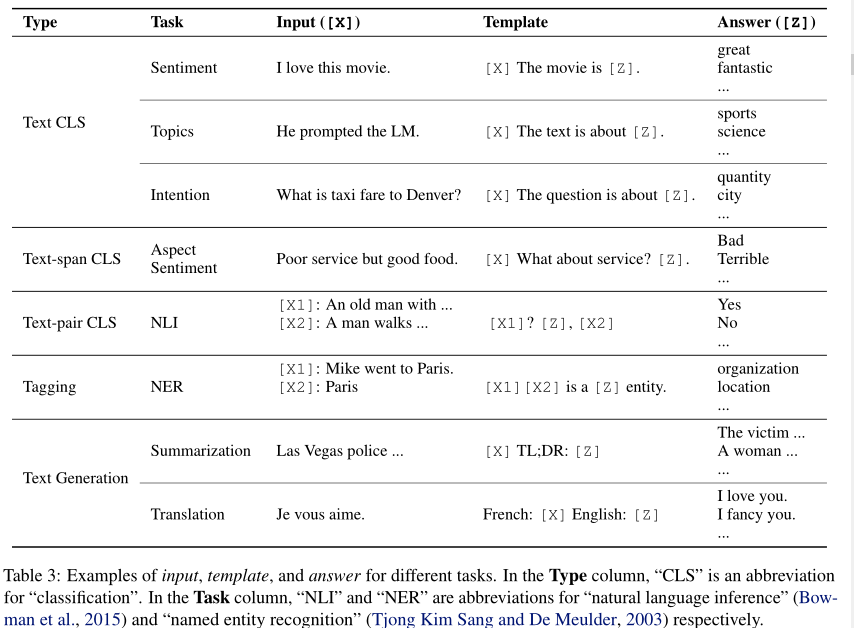
- 应用一个模板,模板有两个slot,其中输入slot [X]给x,答案slot [z]给一个中间生成的答案文本z,z之后会映射为y
- 将slot [X]用x填充
- cloze prompt:[Z]在模板中间;prefix prompt:[Z]在模板尾部
- 模板中的单词不一定是NLP中的token,甚至可以是虚拟的词(用数字来代替,并在之后embed的时候嵌入到连续的空间),甚至prompt函数可以直接生成一个连续的向量
- [X]和[Z]的数目可以灵活调整
Answer Search
- 答案z对应的集合根据不同任务有不同变换,可以是LM字典的子集(在情感分类中,为带有情感的词汇),也可以是整个字典
- 定义函数$f_{fill}(x’,z)$,将[Z]用答案z填充,其结果称为filled prompt(已填充提示),填充结果正确则称answered prompt
- 计算相应已填充提示概率的概率:$\hat z=search_{z\in Z}P(f_{fill}(x’,z);\theta)$,搜索函数可以是argmax搜索,也可以是从字典中采样
Answer Mapping
- 一些情况下,已填充提示本身就是最终输出(例如翻译任务)
- 一些情况下,还需要将填充的答案映射为y(例如情感分类)
Prompt的设计考虑
- 预训练模型的选择(Section3),Prompt Engineering(选择合适的$f_{prompt}(x)$,Section4),Answer Engineering(设计Z,Section5),扩展范例(其他范式,Section6),Prompt-based 训练策略(Section7)
预训练模型
Training Objectives
- SLM(Standard Language Model):自回归预测文本,从左到右
- 有时会给输入本文加噪音,然后在给定噪音文本情况下预测原始输入句子$P(x|\hat x)$
- CTR(Corrupted Text Reconstruction):只计算输入句子中有噪声部分的损失,将处理过的文本恢复到未被破坏的状态
- FTR(Full Text Reconstruction):计算输入文本整体上的损失,无论输入文本是否有噪声
- SLM和FTR训练的模型更适合NLG
- 重构为目标的训练更适合cloze prompt
- 其他预训练目标:
- NSP(Next Sentence Prediction )
- SOP(Sentence Order Prediction)
- CWP(Capital Word Prediction):每个单词的二分类,预测每个单词是否大写
- Finbert: A pre-trained financial language representation model for financial text mining,IJCAI 2020
- SDS(Sentence Deshuffling):多分类任务,用于重新组织permuted segment
- Finbert: A pre-trained financial language representation model for financial text mining,IJCAI 2020
- SDP(Sentence distance prediction):三类分类任务,预测两个句子之间的位置关系(同一文档相邻、同一文档不相邻、在不同文档)
- Finbert: A pre-trained financial language representation model for financial text mining,IJCAI 2020
- MCP(Masked Column Prediction):给定一个表,恢复被屏蔽列的名称和数据类型
- Tabert: Pretraining for joint understanding of textual and tabular data,ACL 2020
- LVA(Linguistic-Visual Alignment):二分类,文本内容是否与可视内容对齐——Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,NeurIPS 2019
- IRP(Image Region prediction):给定部分特征被屏蔽(归零)的图像,预测屏蔽区域
- VL-BERT: pre-training of generic visual-linguistic representations,ICLR 2020
- RTD(Replaced Token Detection):二分类,预测加噪输入中的每个token是否被生成样本替换
- Ernie-gram: Pre-training with explicitly n-gram masked language modeling for natural language understanding,NAACL-HLT 2021
- DRP(Discourse Relation Prediction):预测两个句子之间的语义或修辞关系
- ERNIE 2.0: A continual pre-training framework for language understanding,AAAI 2020
- TLM(Translation Language Modeling):平行语料,在源句和目标句中随机屏蔽单词
- Cross-lingual language model pretraining,2019
- IRR(Information Retrieval Relevance):预测两个句子的信息检索相关度
- ERNIE 2.0: A continual pre-training framework for language understanding,AAAI 2020
- TPP(Token-Passage Prediction):识别段落中出现的段落关键词
- Finbert: A pre-trained financial language representation model for financial text mining,IJCAI 2020
- UKTP(Universal Knowledge-Text Prediction ):知识整合到一个预训练LM中
- ERNIE 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation,CoRR 2021
- MT(Machine Translation):从源语言翻译成目标语言
- mt6: Multilingual pretrained text-to-text transformer with translation pairs,CoRR 2021
- TPSC(Translation Pair Span Corruption):从一对翻译来预测masked span
- mt6: Multilingual pretrained text-to-text transformer with translation pairs,CoRR 2021
- TSC(Translation Span Corruption):与TPSC不同,TSC仅屏蔽和预测一种语言的span
- mt6: Multilingual pretrained text-to-text transformer with translation pairs,CoRR 2021
- MRTD(Multilingual Replaced Token Detection):用一个GAN来区分来自加噪多语言句子的真实输入token,其中生成器和鉴别器跨语言共享
- XLM-E: cross-lingual language model pre-training via ELECTRA,CoRR 2021
- TRTD(Translation Replaced Token Detection):通过GAN来区分翻译对中的真实token和屏蔽token
- XLM-E: cross-lingual language model pre-training via ELECTRA,CoRR 2021
- KE(Knowledge Embedding):将知识图(KGs)中的实体和关系编码为分布式的表示
- KEPLER: A unified model for knowledge embedding and pre-trained language representation,TACL 2021
- ITT(Image-to-text transfer):为输入图像生成相应的图像描述
- KEPLER: A unified model for knowledge embedding and pre-trained language representation,TACL 2021
- MTT(Multimodality-to-text transfer):基于视觉信息和加噪的语言信息生成目标文本
- KEPLER: A unified model for knowledge embedding and pre-trained language representation,TACL 2021
Noise Functions

- Masking:mask可以随机选择,也可以专门设计以引入先验知识,例如将mask集中在句子的实体上
- Replacement:用另一个token或另一个span替换
- Deletion:将token或多个连续token从文本删除,不添加mask token或任何其他token(通常与FTR一起使用)
- Permutation:将文本分成不同的span(token、span、句子),将这些span区间重排成新的文本
表征的方向性
- left-to-right:每个单词的表示根据单词本身和前面的所有单词计算的
- bidirectional:每个单词的表示是基于句子中的所有单词计算的
- 其他方式:二者混合、随机permuted
- 通常通过注意力掩蔽来实现
典型的预训练方法
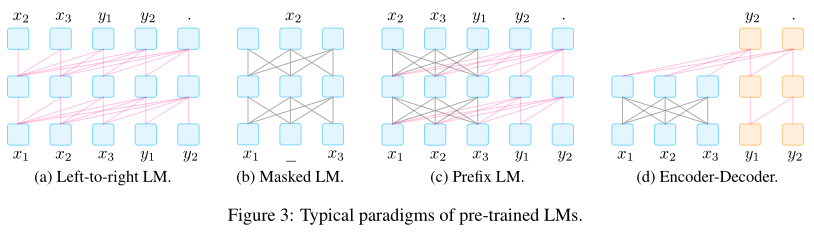
- Left-to-Right LM:自回归,链式法则从左到右
- MLM:最适合NLU任务,也很适合与prompt在微调过程中合用
- Prefix and Encoder-Decoder:条件文本生成任务,编码输入文本并生成输出文本
- Prefix LM:从左到右的LM,基于前缀序列解码y,前缀序列将使用相同的参数编码,但会使用一个fully-connected mask;除了在y上用SLM作为训练目标,还会对x加入噪音并重构文本——Unilm系列、ERNIE-M
- Encoder-decoder:独立的encoder编码x,同样可以对x加入各种噪音——MASS、BART、T5
- 二者自然地适用于prompt,而其他非生成任务同样可以通过提供合适的prompt重构为生成任务(
论文这里有一些引用文献)
Prompt Engineering
Prompt Shape
- 生成任务,或用自回归LM解决的任务通常使用prefix prompt
- 用MLM解决的任务通常使用cloze prompt
- 全文重建的模型更加通用,可cloze prompt或prefix prompt同时使用
- 对于涉及多个输入的任务(如文本对分类),prompt模板必须包含两个或者更多的输入slot
人工模板工程
- 手工设计prompt
自动模板工程
人工模板的问题:创建和试验手工prompt费时且需要充分经验,并且很可能无法人工发现最佳的prompt
离散的prompt:prompt是文本字符串
- Prompt Mining:
- 给定一组训练输入和输出的情况下自动寻找模板
- 从大型语料库(如维基百科)中搜寻包含x和y的字符串,并记录x和y的中间词或依赖路径,频繁出现的中间词或依赖路径作为模板(“[X] middle words [Z]”
- Prompt Paraphrasing:
- 使用现有的种子prompt(例如,手动构建或挖掘),将其解释为一组其他候选prompt,选择在目标任务上实现最高训练准确度的prompt
- 可通过多种方式完成,包括round-trip translation
- Gradient-based Search:
- 对tokens应用基于梯度的搜索,以找到一个短序列,来让预训练LM生成目标预测
- Prompt Generation:
- 将prompt的生成视为文本生成任务
- 有人用T5来做模板搜索
- Prompt Scoring
- Prompt Mining:
连续的prompt:prompt直接用LM的嵌入空间表示,此时模板有自己的参数,可以根据下游任务的训练数据调整
Prefix Tuning:一系列连续的特定于任务的向量添加到输入,同时保持LM参数不变,这要求给定可训练前缀矩阵$M_\phi$和一个固定的预训练模型(参数为$\theta$)下,最大化对数似然:$max_\phi logP(y|x;\theta;\phi)=max_\phi\sum_{y_i}logP(y_i|h_{<i};\theta;\phi)$
- 其中$h_{<i}$是时间步$i$下所有神经网络层的串联,如果相应的时间步在前缀里,则直接从$M_\phi$中复制,否则使用预训练的LM计算得到
Tuning Initialized with Discrete Prompts:
initialize the search for a continuous prompt using a prompt that has already been created or discovered using discrete prompt search methods
Hard-Soft Prompt Hybrid Tuning:在hard prompt template中插入一些可调的embedding,例如P-tuning
Answer Engineering
- 旨在搜索一个答案空间$Z$,和一个原始输出$Y$的映射,从而产生有效的预测模型
Answer Shape
- 答案的shape代表其粒度,包括:token(预训练LM的字典,或者字典的子集)、span(连续的多个token,通常用于cloze prompt)、sentence(句子或文档,通常和prefix prompt共用)
- token或者span通常用于分类任务、关系提取、命名实体识别,而sentence级别和较长短语级别的答案通常用于文本生成任务,或者多项选择问答
答案空间设计方法
- 手工设计
- 答案空间$Z$就是所有tokens、定长的span或者token序列,此时直接将答案$z$映射到最终输出$z$即可
- 如果是命名实体识别等分类问题,输出空间是受限的
- 离散的答案搜索
- Answer Paraphrasing:初始化一个答案空间$Z’$,使用paraphrasing扩展答案空间。给定一对答案和输出$(z’,y)$,计算候选答案集合中各个候选相应的概率,选择其中概率最大的候选作为问题的答案
- Prune-then-search:先对答案候选空间进行裁剪,然后再通过算法去搜索得到最终的答案候选
- Label Decomposition:将类别标签分解为多个token作为该类别的候选答案
- 连续的答案搜索
- 此方面的工作较少,主要使用梯度下降法优化的soft answer tokens
Multi-Prompt Learning
- 以上都是一个输入对应一个单独的prompt
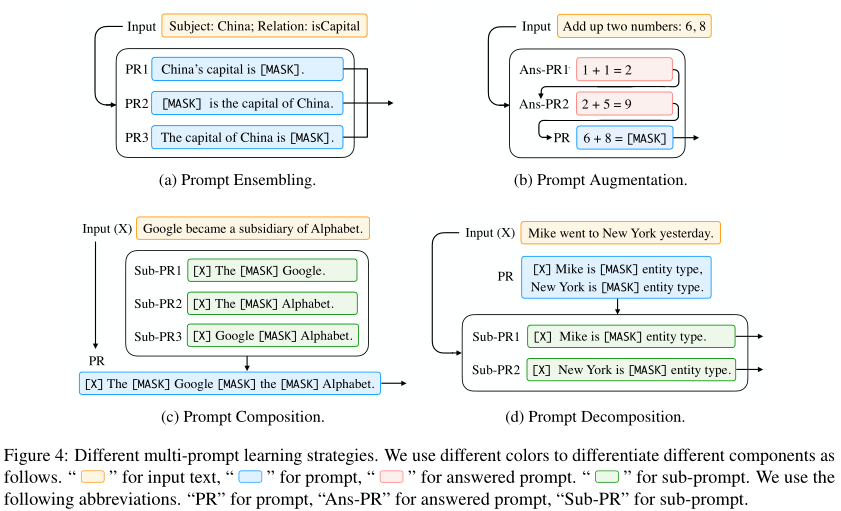
Prompt Ensembling
- 使用多个没有答案的prompt在推理阶段去做最终的,prompt可以是离散或连续的
- 有点像机器学习中集成多个方法
- Uniform averaging:对不同prompt的概率取均值,即$P(z|x)=\frac{1}{K}\sum_i^KP(z|f_{prompt,i}(x))$
- Weighted averaging:带权平均,每个prompt的权重取决于其在训练集上的表现
- Majority voting
- Knowledge distillation:多个深度学习模型可以提高性能,而这种卓越的性能可以使用知识蒸馏提炼成单个模型
- Prompt ensembling for text generation:此时答案为token串;基于答案序列中下一个单词的集合概率生成输出
Prompt Augmentation
- 提供一些额外的answered prompts,帮助LM知道如何为实际的输入x提供答案,例如Great Britain’s capital is London . Japan’s capital is Tokyo . China’s capital is [Z]
- Sample Selection:计算example与输入句子在embedding空间中的距离。选择距离较小的example
- Sample Ordering:example在prompt中的顺序对结果影响很大,可以用entropy-based的方法计算不同候选排列的得分
Prompt Composition
- 一些组合的任务由基础的子任务组成,使用多个针对子任务的prompt,然后设计组合策略来拼接这些prompt
Prompt Decomposition
- 一些需要多种预测值的任务(序列标注),很难直接对输入文本x设计一个完整的prompt
- 直观的想法是把prompt转为多个不同的sub-prompts,对每一个sub-prompt寻找答案
Training Strategies for Prompting Methods
训练设置
- zero-shot setting:简单地采用已被训练用于预测$P(x)$的LM来预测slot
- full-data learning:大量的训练数据用于训练模型
- few-shot learning:少量训练数据
参数更新方法
LM的参数、prompt的参数
五种调优策略如下:(底层LM参数是否已经调优?是否存在与prompt相关的参数?与prompt相关的参数是否已经调优?)
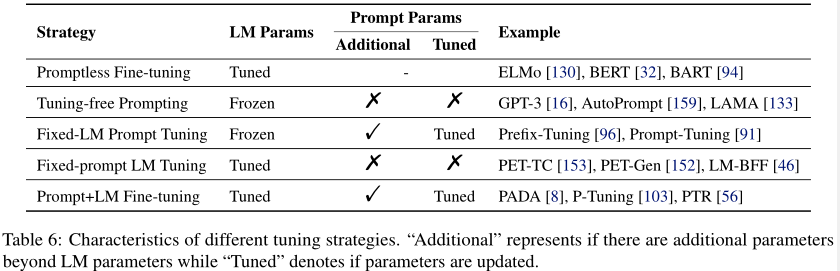
Promptless Fine-tuning:只有预训练+微调
Tuning-free Prompting:仅根据提示直接生成答案,不改变预训练LM参数,也被称为无语境学习(in-context learning),适合zero-shot setting
Fixed-LM Prompt Tuning:除了预训练LM的参数,还引入额外的prompt相关参数。仅使用下游样本的监督信号来更新prompt的参数,适合few shot,通常比第二种更新方法更好
Fixed-prompt LM Tuning:调整LM参数,固定prompt参数
Prompt+LM Tuning:prompt参数和LM参数一起微调
应用
- 知识探索
- 基于分类的任务
- 信息抽取
- 问答
- 文本生成
- prefix prompt+自回归LM
- Language models are unsupervised multitask learners,2019
- Language models are few-shot learners,2020
- Few-shot text generation with pattern-exploiting training,2020
- Prefix-tuning: Optimizing continuous prompts for generation,2021
- GSum: A general framework for guided neural abstractive summarization,2021
- 文本生成的自动评估
- 多模态
Table7、Table8列出了应用(这两个表没看明白,里面有些模型没有用到prompt?)
与Prompt相关的学习方法
略
挑战
略

