MIT-6.830 Lab2 总结与备忘
- Lab2为SimpleDB设计操作符,以实现表的修改(insert和delete tuple)、selection、join和aggregate,以得到一个对多个表进行简单查询的数据库系统
- Lab2要设计一个bufferpool中Page的淘汰策略,本Lab不需要实现事务(transaction)或锁
- SimpleDB OpIterator类实现关系代数的操作
Exercise 1
思路整理
- Implement the skeleton methods in:
src/java/simpledb/execution/Predicate.java、src/java/simpledb/execution/JoinPredicate.java、src/java/simpledb/execution/Filter.java、src/java/simpledb/execution/Join.java,通过PredicateTest、JoinPredicateTest、FilterTest和JoinTest单元测试,和系统测试FilterTest和JoinTest - 代码已经实现了Project(投影,即指定列输出)和OrderBy(按指定字段排序输出)
Filter:返回满足 “谓词 “的tuple ,而”谓词”是其构造函数的一部分(A predicate is an expression that evaluates to True or False)——属性Predicate是用来判断的谓词,属性OpIterator是用来具体轮询的操作符。类比select * from x where a> 3, Predicate代表的是a>3式子,OpIterator用来将tuple传入谓词,获得过滤后的tuplePredicate.java比较表内的字段和提供的数据,三个构造器参数分别是待比较的字段序号、比较符和待比较的数,filter()方法输入一个Tuple,比较Tuple的Field是否符合预期——即Tuple相应字段序号的字段,在该比较符下,是否和待比较数相似Filter.java在构造函数中实例化Predicate和OpIterator。fetchNext()方法逐个读取OpIterator的Tuple,然后比较它们与Predicate的Field,为真则返回该Tuple
Join:根据构造函数参数 “JoinPredicate”来连接其两个子tuple,即满足条件的1 2 3和4 5 6会合并为1 2 3 4 5 6;同样类比下,select * from s1, s2 where s1.field1> s2.field2,要在对两个表s1和s2构造出的笛卡尔积上,找到满足s1.field1 >s2.field2的tuple,那么对应的s1就是child1,s2就是child2JoinPredicate.java和Predicate.java类似,实现两个Tuple 的比较,根据构造器参数和构造器Join.java是对JoinPredicate.java的使用,构造函数实例化JoinPredicate和两个OpIterator,并要实现诸多get和open、close等迭代器函数fetchNext()找两个迭代器中可以join的字段来join,用两个while循环来遍历,直到最外层迭代器遍历完成
具体实现
多读下函数前面的注释,类的属性也基本可以通过构造器的参数确定下来
需要注意的是,哪个tuple调用compare
注意Operator implements OpIterator,而Operator是抽象类,Filter extends Operator(上一个lab的SeqScan中,Iterator是DBfile的iterator)
OpIterator 中的
next()returns the next tuple from the operatorchild是指运算的子项?
Filter的几个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25protected Tuple fetchNext() throws NoSuchElementException,
TransactionAbortedException, DbException {
// some code goes here
while (this.child.hasNext()) {
Tuple curTuple = this.child.next();
if (this.p.filter(curTuple)) { // apply the predicate to next tuple
return curTuple; // 如果符合,则返回这个tuple
}
}
return null;
}
public OpIterator[] getChildren() {
// some code goes here
return new OpIterator[]{this.child}; // 参考Operator.java中的注释
}
public void setChildren(OpIterator[] children) {
// some code goes here
if (children == null) {
return;
}
this.child = children[0]; // 参考Operator.java中的注释
}Join的fetchNext实现中,要考虑到如果本轮对child1的迭代里,有多个符合要求的tuple该如何处理,以及边界情况:最后一个child1的tuple的迭代。写的时候要注意iterator的特点,特别是在第二个while中,返回之前一定要判断是否需要重置(或者说,是否需要执行return外面的代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45private Tuple curTuple;
protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
while (this.child1.hasNext() || this.curTuple != null) { // 第二个判断条件,如果curTuple是child1的最后一个tuple
if (this.child1.hasNext() && this.curTuple == null) {
this.curTuple = this.child1.next();
}
while (this.child2.hasNext()) {
Tuple tuple2 = this.child2.next();
if (this.p.filter(this.curTuple, tuple2)) {
TupleDesc newDesc = TupleDesc.merge(
this.curTuple.getTupleDesc(),
tuple2.getTupleDesc()
);
Tuple result = new Tuple(newDesc); // 建立新的tuple,newDesc使得该tuple的数值为空,但记录了字段属性
// 将两个tuple的内容填充到新的tuple中
int fieldIndex = 0;
for (; fieldIndex < this.curTuple.getTupleDesc().numFields(); fieldIndex++) {
result.setField(fieldIndex, this.curTuple.getField(fieldIndex));
}
for (;
fieldIndex < this.curTuple.getTupleDesc().numFields() + tuple2.getTupleDesc().numFields();
fieldIndex++) {
result.setField(
fieldIndex,
tuple2.getField(fieldIndex - this.curTuple.getTupleDesc().numFields())
);
}
if (!this.child2.hasNext()) {
this.child2.rewind();
this.curTuple = null;
}
return result;
}
}
// 遍历结束,child2重置,curTuple归null
this.child2.rewind();
this.curTuple = null;
}
return null;
}
Exercise 2
思路整理
Implement the skeleton methods in:
src/java/simpledb/execution/IntegerAggregator.java、src/java/simpledb/execution/StringAggregator.java、src/java/simpledb/execution/Aggregate.java,通过IntegerAggregatorTest、StringAggregatorTest和AggregateTest单元测试,和系统测试AggregateTest(实现聚合操作符groupby)SimpleDB操作符用
GROUP BY实现了基本的SQL聚合,这里要实现五个SQL聚合(COUNT,SUM,AVG,MIN,MAX),它们都支持分组SimpleDB使用
Aggregator接口计算聚合,以将一个新tuple合并到已有的聚合计算中Aggregator构造器的参数之一是聚合的具体操作,随后为子迭代器(即child)中的每个tuple调用Aggregator.mergeTupleIntoGroup()。在所有tuple被合并后,可以检索到一个聚合结果的OpIterator,其中的每个tuple都是一对形式为(groupValue, aggregateValue)的元组。如果group by字段的值是Aggregator.NO_GROUPING,其结果是一个形式为(aggregateValue)的元组IntegerAggregator(0, Type.INT_TYPE, 1, Aggregator.Op.SUM)是生成一个整数聚合的对象0表示分组(Group By)字段位置,即根据第零列聚合。如果可以为 NO_GROUPING,表示不进行聚合
Type.INT_TYPE表示这一列的数据类型,目前只有整数和字符串
1表示待聚合的字段
Aggregator.Op.SUM表示执行加法操作
IntegerAggregatorTest测试类中,scan1是一张基础表,
sum/min/max/avg是四张经过聚合操作后的表,用于验证scan1经过聚合后的结果是否符合预期mergeTupleIntoGroup()根据gbField字段先判断是否需要进行group by,需要则根据 gbField从tuple中提取待聚合的字段。接着判断是否是初次填入,根据对应Op执行。如果不需要group by,直接累加即可,不需要映射StringAggregator和IntegerAggregator逻辑类似,String类型的Field只需要实现COUNT运算符
Aggregate是将前两个整合一下,判断一下Field类型,返回IntegerAggregator或StringAggretor即可
具体实现
可以看到,
public IntegerAggregator(int gbfield, Type gbfieldtype, int afield, Op what)中的参数分别表示:分组依据的字段index、分组依据的字段的类型、分组后,对什么字段进行聚合、分组后进行聚合的操作类型。由于要根据不同的组进行聚合,因此存储分组结果最好使用map,并且map的key为Field,值为int(对于IntegerAggregator,要聚合的值都是int)1
2
3
4
5
6
7
8
9
10
11public void mergeTupleIntoGroup(Tuple tup) {
// some code goes here
Field gbField;
if(this.gbfieldIndex == NO_GROUPING) {
gbField = null;
} else {
gbField = tup.getField(this.gbfieldIndex);
}
IntField aField = (IntField) tup.getField(this.afieldIndex);
this.aggHandler.handler(gbField, aField); // 通过map分组,通过hander聚合。key:field中已经包含了分组依据字段的值
}难点在于怎么实现五个聚合操作。将聚合操作封装为GBHandler抽象类,此时上层的IntegerAggregator只需要将其计算后的结果,使用TupleIterator进行封装并返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34private AggHandler aggHandler;
private abstract class AggHandler {
HashMap<Field, Integer> agg;
public AggHandler() {
this.agg = new HashMap<>();
}
public HashMap<Field, Integer> getAgg() {
return this.agg;
}
abstract void handler(Field gbField, IntField aField);
}
private class SumHandler extends AggHandler {
void handler(Field gbField, IntField aField) {
if(this.agg.containsKey(gbField)) {
this.agg.put(gbField, this.agg.get(gbField) + aField.getValue());
} else {
this.agg.put(gbField, aField.getValue());
}
}
}
public class CountHandler extends AggHandler {
void handler(Field gbField, IntField aField) {
if(this.agg.containsKey(gbField)) {
this.agg.put(gbField, this.agg.get(gbField) + 1);
} else {
this.agg.put(gbField, 1);
}
}
}public OpIterator iterator()返回TupleIterator即可,此时需要根据聚合结果,建立TupleDesc和TupleList,具体形式参考上面思路整理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public OpIterator iterator() {
// some code goes here
HashMap<Field, Integer> aggMap = this.aggHandler.getAgg();
ArrayList<Tuple> tupleList = new ArrayList<>();
TupleDesc desc;
if (this.gbfieldIndex == NO_GROUPING) {
desc = new TupleDesc(new Type[]{Type.INT_TYPE}, new String[]{"AggValue"});
Tuple tuple = new Tuple(desc);
tuple.setField(0, new IntField(aggMap.get(null)));
tupleList.add(tuple);
} else {
desc = new TupleDesc(new Type[]{this.gbfieldType, Type.INT_TYPE}, new String[]{"groupByValue", "AggValue"});
for (Map.Entry<Field, Integer> entry: aggMap.entrySet()) {
Tuple tuple = new Tuple(desc);
tuple.setField(0, entry.getKey());
tuple.setField(1, new IntField(entry.getValue()));
tupleList.add(tuple);
}
}
return new TupleIterator(desc, tupleList);
}在写
Aggregate.java时,要明白child代表喂进来的数据,而对数据的迭代需要先对子项完成聚合操作,然后另起一个属性aggregator.iterator()——做的时候有些蒙,没搞明白这些iterator的关系,看了别人的代码才大致清楚些1
2
3
4
5
6
7
8
9
10
11
12public void open() throws NoSuchElementException, DbException,
TransactionAbortedException {
// some code goes here
super.open();
this.child.open();
while (child.hasNext()) {
aggregator.mergeTupleIntoGroup(child.next());
}
this.aggIterator = aggregator.iterator();
this.aggIterator.open();
}
Exercise 3
思路整理
Implement the remaining skeleton methods in:
src/java/simpledb/storage/HeapPage.java、src/java/simpledb/storage/HeapFile.java、BufferPool.java的insertTuple()、deleteTuple(),通过单元测试HeapPageWriteTest、HeapFileWriteTest、BufferPoolWriteTest,实现表格的修改主要操作:添加和删除tuple
- 删除:要实现
HeapFile.deleteTuple()。tuple包含RecordID,从而能找到页面,将该页面中tuple队列的相应位置设置为null,并修改该Page的header - 添加:要实现
HeapFile.insertTuple()。向HeapFile添加一个新元组,要找到一个有空slot的Page,如果没有则创建一个新的Page并追加到磁盘的物理文件中。要确保tuple中的RecordID更新正确 - 以上过程,会使用到
getNumEmptySlots()和isSlotUsed() markSlotUsed()方法可以修改header中对应tuple的状态HeapFile.insertTuple()和HeapFile.deleteTuple()要使用BufferPool.getPage()访问页面,而BufferPool中的添加和删除tuple方法,要调用HeapFile中被修改的table的方法,完整的一次调用过程如下所示。第四步是HeapPage在内存中修改自己的内容
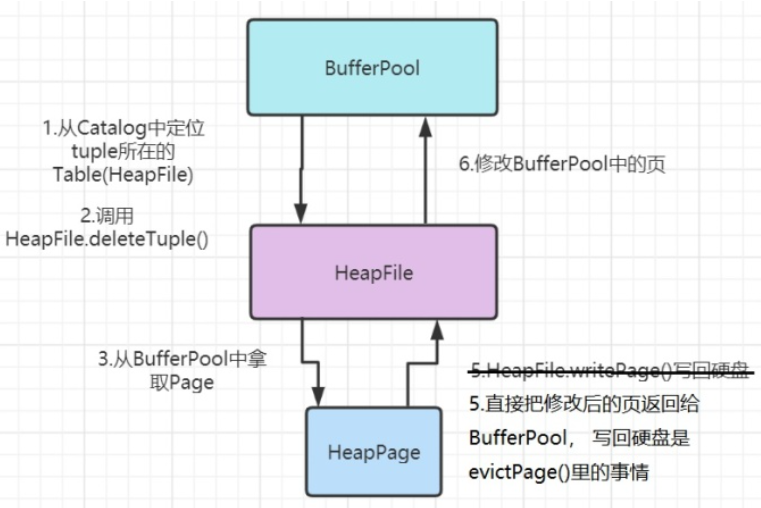
- 删除:要实现
HeapFile不是在内存的File,是对硬盘HeapFile中操作的抽象,HeapPage是被加载到内存中的页
调用过程的文字表述:
删除:
- BufferPool定位tuple所在的table,以及相应的page(
t.getRecordId().getPageId().getTableId()),调用HeapFile.deleteTuple()进行删除 HeapFile检查这个Page是否在BufferPool中,没有则需要从磁盘读取(这一点已经在之前的lab中实现了);定位到相应的page- tuple传给HeapPage,判断是否属于这个Page(Pageid是否相同?Page的tupleDesc和tuple的Desc是否相同?tuple的tupleNo对应的插槽是不是空的?),如果属于,则将Page的这个位置置为null,并通过
markSlotUsed()让相应header的位置归零。注意,header是对bit做处理,因此要使用位运算 - HeapFile此时暂时不将删除了Tuple的Page写入磁盘(因为
HeapFile.deleteTuple()中没有IO异常的抛出) - 由于对Page做了操作,因此对这个Page标记为”脏“(
page.markDirty),并将这个Page加入到BufferPool中(暂时不需要执行淘汰)(由于DbFile的deleteTuple返回的是List<Page>,因此这些Page都要标记为”dirty“,并加入缓冲池)
- BufferPool定位tuple所在的table,以及相应的page(
添加:
BufferPool会给定相应的tableId,因此直接从Catalog找对应的DbFile,调用
HeapFile.insertTuple()进行添加HeapFile检查自己所有的page是否有空的slot,如果有就加过去。如果没有,就新建一个Page,加到这个File中(同样通过HeapFile.writePage()写入,此时会自然地seek到最后一个位置,将Page内容写入后,自然就将Page加入到这个File中),并insertTupletuple传给HeapPage,判断是否属于这个Page(Page的tupleDesc和tuple的Desc是否相同?page满了吗?),如果属于,则遍历这个Page的slot,找一个空的加入tuple,同时设置这个tuple的record,并用
markSlotUsed()标记这个slot被使用HeapFile同样标记这个Page为脏,并将这个Page加入BufferPool
具体实现
final:如果为引用数据类型,比如对象、数组,则该对象、数组本身可以修改,但指向该对象或数组的地址的引用不能修改
BufferPool:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public void insertTuple(TransactionId tid, int tableId, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId);
List<Page> curPage = dbFile.insertTuple(tid, t);
for (Page page: curPage) {
page.markDirty(true, tid);
this.map.put(page.getId(), page);
}
}
public void deleteTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
int tableid = t.getRecordId().getPageId().getTableId();
DbFile dbFile = Database.getCatalog().getDatabaseFile(tableid);
List<Page> curPage = dbFile.deleteTuple(tid, t);
for (Page page: curPage) {
page.markDirty(true, tid);
this.map.put(page.getId(), page);
}
}HeapFile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public void writePage(Page page) throws IOException {
// some code goes here
// not necessary for lab1
RandomAccessFile File = new RandomAccessFile(this.file, "rw"); // 通过RandomAccessFile写
File.seek((long) BufferPool.getPageSize() *page.getId().getPageNumber());
File.write(page.getPageData());
File.close();
}
// see DbFile.java for javadocs
public List<Page> insertTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
List<Page> res = new ArrayList<>();
// 遍历这个DbFile的pages,看有没有空的slot
for (int i = 0; i < this.numPages(); i++) {
HeapPage curPage = (HeapPage) Database.getBufferPool().getPage(
tid,
new HeapPageId(this.getId(), i),
Permissions.READ_WRITE
);
if (curPage.getNumEmptySlots() > 0) {
curPage.insertTuple(t);
res.add(curPage);
this.writePage(curPage);
return res;
}
}
HeapPage curPage = new HeapPage(
new HeapPageId(this.getId(), this.numPages()),
HeapPage.createEmptyPageData()
);
curPage.insertTuple(t);
res.add(curPage);
this.writePage(curPage);
return res;
}
// see DbFile.java for javadocs
public ArrayList<Page> deleteTuple(TransactionId tid, Tuple t) throws DbException,
TransactionAbortedException {
// some code goes here
// not necessary for lab1
PageId pageId = t.getRecordId().getPageId();
HeapPage curPage = (HeapPage) Database.getBufferPool().getPage(tid, pageId, Permissions.READ_WRITE);
curPage.deleteTuple(t);
ArrayList<Page> res = new ArrayList<>();
res.add(curPage);
return res;
}HeapPage:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58/**
* Delete the specified tuple from the page; the corresponding header bit should be updated to reflect
* that it is no longer stored on any page.
*
* @param t The tuple to delete
* @throws DbException if this tuple is not on this page, or tuple slot is
* already empty.
*/
public void deleteTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
if (t.getRecordId().getTupleNumber() >= this.numSlots) { // 判断tuple的tupleNo是否超过Page的限制
throw new DbException("tuple is not on this page");
}
if (!this.td.equals(t.getTupleDesc())) { // tupledesc不匹配,因此不在这个page上
throw new DbException("tuple is not on this page");
}
if (tuples[t.getRecordId().getTupleNumber()] == null) { // 判断该page的相应位置上有没有tuple
throw new DbException("tuple is not on this page");
}
if (!isSlotUsed(t.getRecordId().getTupleNumber())) { // 判断该slot是否为空
throw new DbException("slot is empty");
}
if (!t.getRecordId().getPageId().equals(this.pid)) { // 判断相应位置上的tuple是否相同
throw new DbException("tuple is not on this page");
}
this.tuples[t.getRecordId().getTupleNumber()] = null; // 删除该page存储的tuple
this.markSlotUsed(t.getRecordId().getTupleNumber(), false);
}
/**
* Adds the specified tuple to the page; the tuple should be updated to reflect
* that it is now stored on this page.
*
* @param t The tuple to add.
* @throws DbException if the page is full (no empty slots) or tupledesc
* is mismatch.
*/
public void insertTuple(Tuple t) throws DbException {
// some code goes here
// not necessary for lab1
if (!this.td.equals(t.getTupleDesc())) { // tupleDesc不一致
throw new DbException("tuple should not be inserted in this page");
}
if (this.getNumEmptySlots() == 0) { // Page满了
throw new DbException("page is full");
}
// tuple还没有插入,因此不需要判断Pageid是否相同
// 找一个空的slot,插入tuple
for (int i = 0; i < this.numSlots; i++) {
if (!this.isSlotUsed(i)) {
this.tuples[i] = t;
t.setRecordId(new RecordId(this.pid, i));
markSlotUsed(i, true);
break;
}
}
}此外还发现
HeapFileIterator中的一个bug。HeapFileWriteTest第二个测试中,一个DbFile的第一二、四个Page为空,第三、五个page中有tuple。此时判断hasNext()时,应当循环遍历所有的Page,而不是只更换一次Page错误代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public boolean hasNext() throws DbException, TransactionAbortedException {
System.out.println("asdfasdf");
if (this.iterator == null) {
return false;
}
if (this.iterator.hasNext()) {
return true;
} else {
this.curPageNo += 1;
if (this.curPageNo >= pageNum) {
return false;
}
this.iterator = this.getNextPage(new HeapPageId(this.heapFile.getId(), this.curPageNo));
if (this.iterator == null) {
return false;
}
return this.iterator.hasNext();
}
}修正代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean hasNext() throws DbException, TransactionAbortedException {
for (int i = this.curPageNo; i < this.pageNum; i++) {
if (this.iterator == null) {
return false;
}
if (this.iterator.hasNext()) {
return true;
}
this.curPageNo += 1;
if (this.curPageNo >= pageNum) {
return false;
}
this.iterator = this.getNextPage(new HeapPageId(this.heapFile.getId(), this.curPageNo));
}
return false;
}
Exercise 4
思路整理
Implement the skeleton methods in:
src/java/simpledb/execution/Insert.java、src/java/simpledb/execution/Delete.java,通过单元测试InsertTest,系统测试InsertTest和DeleteTest最顶层的操作符是一个特殊的“插入”或“删除”运算符,修改磁盘上的Page。操作符返回受影响tuple的数量(返回一个带有一个整数字段的元组)
插入:操作符将其从子操作符中读取的tuple,添加到构造函数中指定的
tableid(使用BufferPool.insertTuple())删除:从构造函数中指定的
tableid,删除从子操作符读取的tuple(使用BufferPool.deleteTuple())
具体实现
基本上调用上一个exercise即可,需要注意判断一个Op实例是否已经执行过(增加一个私有属性
hasDeleted,调用fetchNext()时,只有该属性为false时才开始删除。删除完成,设置其为true,insert同样如此)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19protected Tuple fetchNext() throws TransactionAbortedException, DbException {
// some code goes here
if (!this.hasInserted) {
while (this.childOp.hasNext()) {
Tuple tupleDelete = this.childOp.next();
try {
Database.getBufferPool().insertTuple(this.transactionId, this.tableId, tupleDelete);
this.count += 1;
} catch (IOException e) {
e.printStackTrace();
}
}
Tuple tuple = new Tuple(new TupleDesc(new Type[]{Type.INT_TYPE}));
tuple.setField(0, new IntField(this.count));
this.hasInserted = true;
return tuple;
}
return null;
}
Exercise 5
思路整理
Fill in the
flushPage()method and additional helper methods to implement page eviction in:src/java/simpledb/storage/BufferPool.java,通过系统测试EvictionTest实现一个页面淘汰策略,修改先前的读取、创建Page的代码(
flushAllPages()仅用于测试)flushPage和flushAllPages不从缓冲池中淘汰页面,flushAllPages在BufferPool中的所有页面上调用flushPage,flushPage将脏页写入磁盘,并重置为clean,留在BufferPool
唯一从缓冲池中删除页面的方法是evictPage,它应该对它所淘汰的任何脏页面调用flushPage。
discardPage():从缓冲池中删除一个页面,而不flush到磁盘上(本实验不会测试该方法)
LRU比较合适,或者用队列实现一个FIFO,出队时淘汰HashMap里对应的Page并刷盘,把页面的dirty设置为false,此时传入TranstractionId为null
具体实现
淘汰策略选择LRU,同时修改
BufferPool中的map为ConcurrentHashMap<PageId, Node<Page>>,并新增私有属性head和tail,以标识双向链表的头尾——这里双向链表的节点,可以通过Map来快速找到某个PageID的节点,以快速地修改节点在链表的位置。具体代码:更改
BufferPool的构造函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19private final ConcurrentHashMap<PageId, Node<Page>> lruCache; // 防止锁的占用
private final Node<Page> head;
private final Node<Page> tail; // lruCache的头和尾
/**
* Creates a BufferPool that caches up to numPages pages.
*
* @param numPages maximum number of pages in this buffer pool.
*/
public BufferPool(int numPages) {
// some code goes here
this.numPages = numPages;
this.lruCache = new ConcurrentHashMap<>();
this.head = new Node<>();
this.tail = new Node<>();
this.head.setNext(this.tail);
this.tail.setPrev(this.head);
}Node类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public class Node<T> {
private T data;
private Node<T> next;
private Node<T> prev;
public Node() {
this.next = null;
this.prev = null;
}
public Node(T dataVal) {
this.data = dataVal;
this.next = null;
this.prev = null;
}
public void setNext(Node<T> next) {
this.next = next;
}
public void setPrev(Node<T> prev) {
this.prev = prev;
}
public T getData() {
return data;
}
public Node<T> getNext() {
return next;
}
public Node<T> getPrev() {
return prev;
}
}将Page加入到lruCache,以及根据PageID删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public void put(PageId pid, Page curPage) {
// 将curPage放到lruCache的最前面
Node<Page> curNode = new Node<>(curPage);
this.lruCache.put(pid, curNode);
curNode.setNext(this.head.getNext());
this.head.getNext().setPrev(curNode); // 不能忽略这一步
this.head.setNext(curNode);
}
public void removeLast() {
// 淘汰最后一个Node
Node<Page> lastPage = this.getTail();
this.lruCache.remove(lastPage.getData().getId());
Node<Page> prevNode = lastPage.getPrev();
Node<Page> nextNode = lastPage.getNext();
prevNode.setNext(nextNode);
nextNode.setPrev(prevNode);
}
public void remove(PageId pageId) {
// 从中lruCahe中删除一个Page
// 从字典中删除
Node<Page> curNode = this.lruCache.get(pageId);
this.lruCache.remove(pageId);
// 从链表中删除
Node<Page> prevNode = curNode.getPrev();
Node<Page> nextNode = curNode.getNext();
prevNode.setNext(nextNode);
nextNode.setPrev(prevNode);
}
public Node<Page> getTail() {
return this.tail.getPrev();
}修改
BufferPool的getPage方法,以实现页面淘汰1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
Node<Page> curNode = this.lruCache.get(pid);
if (curNode == null) {
if (this.lruCache.size() == this.numPages) {
// 淘汰最后一个Node
this.removeLast();
}
this.put(pid, Database.getCatalog().getDatabaseFile(pid.getTableId()).readPage(pid));
// 从磁盘读出page(page有自己的table id,而table和dbfile一一对应,dbfile是与磁盘交互的接口)
curNode = this.lruCache.get(pid); // 将载入buffer pool的page给到curPage
return curNode.getData();
} else {
this.remove(curNode.getData().getId());
this.put(curNode.getData().getId(), curNode.getData());
return curNode.getData();
}
}
总结
Lab2利用Lab1实现的存储部件,实现了几个操作符。感觉不好理解的是第一、二个exercise中的OpIterator,特别是聚合操作符。后面的增删部分,理解了调用过程就比较顺利
几个存储部件的关系还要再想想
LRU的实现中,HashMap和双向链表结合,实现了快速查找节点,和页面(节点)淘汰
下面是一个检查连接查询的例子,实现语句为
1
2
3
4
5SELECT *
FROM some_data_file1,
some_data_file2
WHERE some_data_file1.field1 = some_data_file2.field1
AND some_data_file1.id > 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53package simpledb;
import java.io.*;
public class jointest {
public static void main(String[] argv) {
// construct a 3-column table schema
Type types[] = new Type[]{Type.INT_TYPE, Type.INT_TYPE, Type.INT_TYPE};
String names[] = new String[]{"field0", "field1", "field2"};
TupleDesc td = new TupleDesc(types, names);
// create the tables, associate them with the data files
// and tell the catalog about the schema the tables.
HeapFile table1 = new HeapFile(new File("some_data_file1.dat"), td);
Database.getCatalog().addTable(table1, "t1");
HeapFile table2 = new HeapFile(new File("some_data_file2.dat"), td);
Database.getCatalog().addTable(table2, "t2");
// construct the query: we use two SeqScans, which spoonfeed
// tuples via iterators into join
TransactionId tid = new TransactionId();
SeqScan ss1 = new SeqScan(tid, table1.getId(), "t1");
SeqScan ss2 = new SeqScan(tid, table2.getId(), "t2");
// create a filter for the where condition
Filter sf1 = new Filter(
new Predicate(0,
Predicate.Op.GREATER_THAN, new IntField(1)), ss1);
JoinPredicate p = new JoinPredicate(1, Predicate.Op.EQUALS, 1);
Join j = new Join(p, sf1, ss2);
// and run it
try {
j.open();
while (j.hasNext()) {
Tuple tup = j.next();
System.out.println(tup);
}
j.close();
Database.getBufferPool().transactionComplete(tid);
} catch (Exception e) {
e.printStackTrace();
}
}
}Lab2的ReadMe最后,介绍了如何自己创建数据表和目录,并使用SimpleDB的query parser编写和运行针对这些数据的SQL查询

