Redis(1)概述与基本数据类型
NoSQL数据库
以性能优先的存储,破坏了业务逻辑
解决性能问题(高访问量、高数据量)
解决CPU的负担
使用一个服务器反代理(nginx),分配访问流量,实现负载均衡
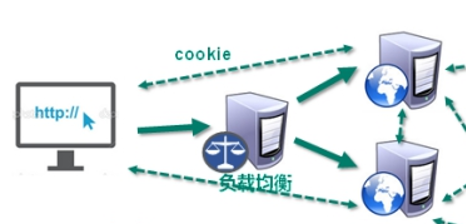
如何保存session?第一次访问时分配给服务器A负责,服务器A保存登录信息到session对象中,第二次访问分配给服务器B负责,但此时B没有session对象,就无法提供服务。解决方案:
方案一:客户端保存cookie,每次访问时都携带cookie,保证session对象能被各个服务器获得——不安全
方案二:session复制,服务器A将session发给服务器B——冗余
方案三:准备一个nossql数据库,A将session对象放到nosql数据库中,B收到访问请求后检查nosql数据库中是否有该session对象(nosql数据库的数据放在内存中,读的速度快)
解决IO压力:频繁查询的数据放到缓存数据库中
概述:
- Not Only SQL
- 不依赖业务逻辑存储,以简单的key-value模式存储
- 不遵循SQL标准
- 不支持ACID(原子性、隔离性、一致性、持久性),但支持事务
- 性能远超SQL
- 适用场景:
- 数据高并发的读写(电商秒杀)
- 海量数据的读写
- 数据要求高可扩展性
- 不适用场景:基于sql的结构化查询存储,处理复杂的关系,需要即席查询
- 常见NoSQL:
- Memcache:数据在内存中,不支持持久化,只支持key-value模式
- Redis:覆盖Memcache功能,支持持久化,单线程+多路IO复用,常作为缓存数据库辅助持久化的数据库
- MongoDB:文档型数据库(存储结构类似于json)
行式存储数据库:将一个表格按行存储
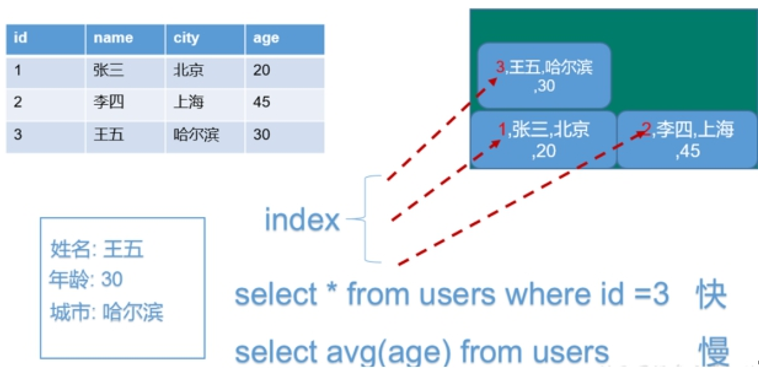
列式存储数据库:将一个表格按列存储
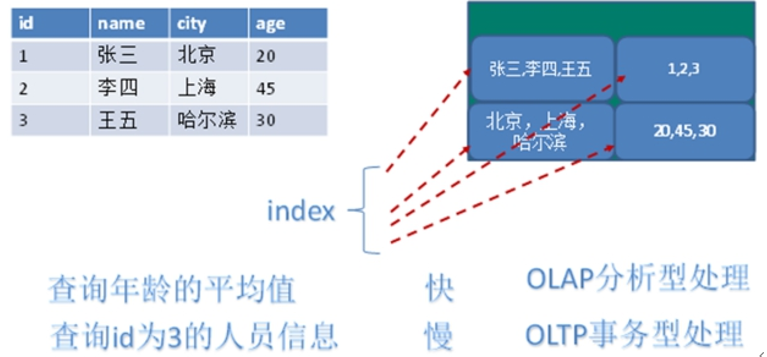
- Hbase(适用于对大量数据做随机、实时的读写操作的场景)
- Cassandra
图关系型数据库(社会关系、公共交通、地图等)
Redis6概述
概述:
- 开源的key-value存储系统
- 支持的value类型:string、list、set、zset(有序集合)、hash,并支持push/pop、add/remove、取交集并集差集操作(均为原子)
- 数据缓存在内存,但周期地把更新的数据写入磁盘,或把修改操作追加到记录文件
- 实现master-slave(主从)同步
应用场景:
- 配合关系型数据库做高速缓存(降低数据库IO、用于分布式架构实现session共享)
- 多种数据结构存储持久化数据
- 最新N个数据:list数据按时间排序
- 排行榜:zset
- 时效性数据:Expire
- 计数器、秒杀:原子的自增方法INCR、DECR
- 订阅消息系统:pub/sub模式
Redis安装目录:
- redis-benchmar:本地性能测试工具
- redis-check-aof:修复有问题的AOF文件
- redis-check-dump:修复有问题的dump.rdb文件
- redis-sentinel:Redis集群
- redis-server:Redis服务器启动
- redis-cli:Redis客户端,操作的入口
启动与关闭:
后台启动(windows不支持)
略,大致过程为,修改redis.conf文件,运行
redis-server ./redis.conf;要运行客户端则执行redis-cli,或者redis-cli -p 6379关闭redis:
- 运行
redis-cli shutdown - 关闭指定端口:
redis-cli -p 6379 shutdown
- 运行
默认端口号6379
redis默认有16个数据库,从0开始,初始时默认使用0号数据库
select <dbid>切换数据库,select 8所有库的密码相同
dbsize查看当前数据库的key的数量flushdb清空当前库flushall清空全部库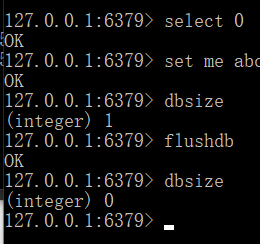
支持单线程+多路IO复用,实现类似多线程+锁的效果
- 串行操作:一个操作完成后再进行下一个操作
- 多线程+锁(memcached使用)
- 单线程+多路IO复用:使用一个线程来检查多个文件描述符(Socket)的就绪状态,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。文件描述符得到就绪状态后,真正的操作可以在同一个线程里执行,也可以启动新的线程执行
Redis数据类型
(以下数据类型为value的数据类型,默认key数据类型为String)
key操作
keys *:查看当前库所有key(匹配:keys *1)exists <key>:判断某个key是否存在type <key>:查看key是什么类型del <key>:删除指定的key数据unlink <key>:根据value选择非阻塞删除——仅将key从keyspace中删除,实际数据的删除会在之后异步进行expire <key> 10:为给定的key设置过期时间为10sttl <key>:查看key还有多少秒过期,-1表示永不过期,-2表示已过期1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29127.0.0.1:6379> set k1 lucy
OK
127.0.0.1:6379> set k2 mary
OK
127.0.0.1:6379> set k3 jack
OK
127.0.0.1:6379> keys *
1) "k2"
2) "k3"
3) "k1"
127.0.0.1:6379> exists k1
(integer) 1
127.0.0.1:6379> exists k4
(integer) 0
127.0.0.1:6379> type k2
string
127.0.0.1:6379> del k3
(integer) 1
127.0.0.1:6379> keys *
1) "k2"
2) "k1"
127.0.0.1:6379>expire k1 10
(integer) 1
127.0.0.1:6379> ttl k1
(integer) 4
127.0.0.1:6379> ttl k1
(integer) -2
127.0.0.1:6379> get k1
(nil)
String
二进制安全——Redis的string可以包含任何数据,如jpg图片、序列化的对象
字符串value最大为512M
常用命令
取值:
set <key> <value>:
- NX:key不存在时,将key-value添加数据库
- XX:key存在时,将key-value添加数据库,与NX参数互斥
- EX:key超时秒数
- PX:key超时毫秒数,与EX互斥
get <key>:查询value
append <key> <value>:将value追加到原值末尾,返回总的value长度(仍然为上面的例子)1
2
3
4127.0.0.1:6379> append k2 123
(integer) 7
127.0.0.1:6379> get k2
"mary123"strlen <key>:获得值的长度setnx <key> <value>:在key不存在时设置key的值,如果返回0,表明设置失败增减:
incr <key>:将key对应的数字值增1(只对数字值操作,如果为空,结果为1),原子- 原子:不被线程调度机制打断,这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch(切换到另一个线程)
- Redis单命令的原子性来源于Redis的单线程
decr <key>:将key对应的数字值减1(只对数字值操作,如果为空,结果为-1),原子incrby / decrby <key> <步长>:增减key对应的数字值,自定义增减的量
取多个值:
mset <key1> <value1> <key2> <value2> .....:同时设置一个或多个key-valuemget <key1> <key2> <key3> .....:同时获取一个或多个valuemsetnx <key1> <value1> <key2> <value2> .....:同时设置一个或多个key-value,当且仅当所有给定key不存在——原子性,有一个失败则都失败
getrange <key> <起始位置> <结束位置>:获得值的范围,前闭、后闭setrange <key> <起始位置> <value>:用value 覆写key所储存的字符串值,从起始位置开始(索引从0开始)setex <key> <过期时间> <value>:设置键值的同时,设置过期时间,单位秒getset <key> <value>:设置新value,同时获得旧value
数据结构:
- String数据结构为简单动态字符串(Simple Dynamic Strin,SDS)
- 内部结构实现类似于Java的ArrayList,预分配冗余空间,以减少内存的频繁分配(capacity通常高于实际的字符串长度len),扩容时对现有的空间加倍,但如果超过1M,扩容时一次只多扩1M
List
字符串列表,按照插入顺序排序,可以添加元素到列表头部或尾部
常用命令:
lpush/rpush <key> <value1> <value2> <value3> ....:从左边/右边push一个或多个值——如果为lpush,则列表中元素顺序为:value3、value2、value1lpop/rpop <key>:从左边/右边pop出一个值,如果列表为空,则key被删除rpoplpush <key1> <key2>:列表key1右边pop出一个值,push到列表key2左边lrange <key> <start> <stop>:按照索引下标获得元素(从左到右)——lrange mylist 0 -1,获得所有元素lindex <key> <index>:获得索引index的元素llen <key>:获得列表长度linsert <key> before/after <value> <newvalue>:在value的前/后面插入newvalue1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19127.0.0.1:6379> rpush a 10 20 30 lucy mary jack
(integer) 6
127.0.0.1:6379> lrange a 0 -1
1) "10"
2) "20"
3) "30"
4) "lucy"
5) "mary"
6) "jack"
127.0.0.1:6379> linsert a BEFORE lucy 40
(integer) 7
127.0.0.1:6379> lrange a 0 -1
1) "10"
2) "20"
3) "30"
4) "40"
5) "lucy"
6) "mary"
7) "jack"lrem <key> <n> <value>:从左边删除n个value1
2
3
4
5
6
7
8
9127.0.0.1:6379> rpush b 10 10 10 lucy mary jack
(integer) 6
127.0.0.1:6379> lrem b 2 10
(integer) 2
127.0.0.1:6379> lrange b 0 -1
1) "10"
2) "lucy"
3) "mary"
4) "jack"lset <key> <index> <value>:将列表key下标为index的值替换成value(从0老开始)
数据结构:双向链表,端的操作性能高,索引下标操作中间节点性能较低
数据结构为快速链表(quickList)
列表元素较少时,使用一块连续的内存(压缩列表,ziplist)存储,所有元素紧挨;链表和ziplist结合起来组成quickList
普通的链表需要的附加指针空间太大,会浪费空间。这样的组合满足了快速的插入删除性能,并且不会出现太多的空间冗余

Set
无重复元素,字符串的无序集合,添加、删除、查找的复杂度为O(1)
常用命令:
sadd <key> <value1> <value2> .....:将一个或多个元素加入集合key,已有的元素被忽略smembers <key>:获得该集合的所有值sismember <key> <value>:判断集合key是否含有value,有则返回1,没有则返回0scard <key>:返回集合的元素个数srem <key> <value1> <value2> ....:删除集合的元素spop <key>:该集合随机pop一个值,如果集合为空,则该集合被删除srandmember <key> <n>:随机从该集合取出n个值(不从集合删除 )smove <source> <destination> <value>:把集合source中的value,移动到集合destinationsinter <key1> <key2>:返回两个集合的交集元素sunion <key1> <key2>:返回两个集合的并集元素sdiff <key1> <key2>:返回两个集合的差集元素(key1中有,key2中没有)
数据结构:底层是一个value为null的hash表(value都指向同一个内部对象,类似java中的HashSet)
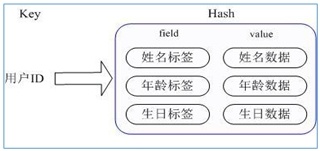
Hash
hash是一个string类型的field和value的映射表,类似Java的
Map<String, Object>(可以认为key是变量名,保存一个dict)例如,用户ID为key,field为用户的属性,value为属性值
常用命令:
hset <key> <field> <value>:给key的field键赋值valuehget <key1> <field>:从key中的field取出 valuehmset <key1> <field1> <value1> <field2> <value2>...:批量设置field-valuehexists <key1> <field>:查看key中,给定field是否存在hkeys <key>:列出key的所有fieldhvals <key>:列出key的所有valuehincrby <key> <field> <increment>:key中field的值增加incrementhsetnx <key> <field> <value>:key中的field设置为value,当且仅当field不存在
数据结构
- 两种数据结构:ziplist(压缩列表)、hashtable(哈希表)
- field-value长度较短且个数较少时,使用ziplist,否则使用hashtable
ZSet
zset与set相似,是没有重复元素的字符串集合,但每个元素都关联了一个评分score,score用于升序排列集合中的成员——可以使用zset作为一个没有重复成员的智能list
常用命令:
zadd <key> <score1> <value1> <score2> <value2>…:将一个或多个元素及其score加入zset keyzrange <key> <start> <stop> [WITHSCORES]:返回zset key中,下标在start和stop之间的元素。带WITHSCORES,分数同时返回zrangebyscore key minmax [withscores] [limit offset count]:返回key中,score在min和max 之间(包括min、max)的value,按score递增排列zrevrangebyscore key maxmin [withscores] [limit offset count]:同上,递减排列zincrby <key> <increment> <value>:为value的score加上增量zrem <key> <value>:删除该集合下的指定valuezcount <key> <min> <max>:统计该集合,区间[min, max]内的value个数zrank <key> <value>:返回value在集合中的排名,从0开始
数据结构:
类似于Java的
Map<String, Double>和TreeSet底层使用两个数据结构:
hash:关联value和score,保证value唯一,通过value找相应score
跳跃表:给value排序,并根据score的范围获取元素列表
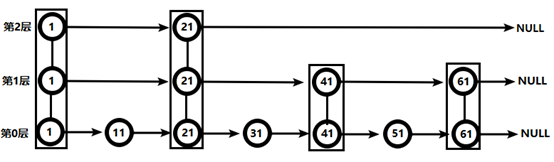
- 查找值为51的元素,从第2层开始,1比51小,向后比较,21比51小,继续向后比较,后面是NULL,因此从节点21向下到第1层
- 第1层,41比51小,继续向后,61比51大,因此从41向下到第0层
- 第0层,51节点为要查找的节点。共查找4次
Redis6的新数据类型
Bitmaps
操作位(bit),本身不是一种数据类型(其实就是字符串类型的value),但可以对字符串的位进行操作——以位为单位的数组,元素为0和1,下标为offset
下图为字符串abc对应的位数组

常用命令:
- setbit:
setbit <key> <offset> <value>:设置bitmaps中某个offset的值(0或1) - getbit:
getbit <key> <offset>:获取Bitmaps中某个偏移量的值(从0开始) - bitcount:
bitcount <key> [start end]:统计字符串从start字节到end字节中(包含start和end),bit为1的数量。-1表示最后一位,-2表示倒数第二位 - bitop:
bitop and(or/not/xor) <destkey> [key…]:做多个Bitmaps的and 、or 、not 、xor操作,结果保存在destkey
- setbit:
一个应用:
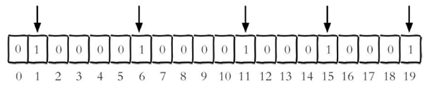
用bitmaps记录网站某天访问过的独立用户(假设注册用户有20个,如果用户访问过,则相应用户id作为下标,设置为1)
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> setbit user:0723 1 1
(integer) 0
127.0.0.1:6379> setbit user:0723 6 1
(integer) 0
127.0.0.1:6379> setbit user:0723 11 1
(integer) 0
127.0.0.1:6379> setbit user:0723 15 1
(integer) 0
127.0.0.1:6379> setbit user:0723 19 1
(integer) 0第1字节到第3字节的访问用户数(11,15,19)
1
2127.0.0.1:6379> bitcount user:0723 1 3
(integer) 3再次记录一天的用户访问,计算任意一天都访问过的用户数目
1
2
3
4
5
6
7
8127.0.0.1:6379> setbit user:0724 1 1
(integer) 0
127.0.0.1:6379> setbit user:0724 6 1
(integer) 0
127.0.0.1:6379> setbit user:0724 9 1
127.0.0.1:6379> bitop or user:0723-0724 user:0723 user:0724(integer) 3
127.0.0.1:6379> bitcount user:0723-0724
(integer) 6
HyperLogLog
求集合中不重复元素个数的问题,称基数问题
HyperLogLog用于做基数统计,在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、很小的——每个HyperLogLog键只需要花费12 KB内存,就可以计算接近$2^{64}$个不同元素的基数
HyperLogLog只根据输入元素计算基数,不储存输入元素本身,无法返回输入的元素
常用命令:
pfadd <key> <element> [element ...]:添加element到HyperLogLog key中,如果执行后HLL估计的近似基数发生变化,返回1,否则返回01
2
3
4127.0.0.1:6379> pfadd a "redis" "hadoop"
(integer) 1
127.0.0.1:6379> pfadd a "redis"
(integer) 0pfcount <key> [key ...]:计算HLL(多个)的近似基数,如果为多个,则返回它们的”和“1
2
3
4
5
6
7
8127.0.0.1:6379> pfadd b "redis"
(integer) 1
127.0.0.1:6379> pfcount a b
(integer) 2
127.0.0.1:6379> pfadd c "cur"
(integer) 1
127.0.0.1:6379> pfcount a b c
(integer) 3pfmerge <destkey> <sourcekey> [sourcekey ...]:一个或多个HLL合并后的结果存储在另一个HLL中
Geospatial
- 该类型是元素的2维坐标(地图上就是经纬度)
- 提供经纬度设置和查询、范围查询、距离查询、经纬度Hash等操作
- 常用命令:
geoadd <key> <longitude> <latitude> <member> [longitude latitude member...]:添加地理位置(经度,纬度,名称)——有效的经度为-180度到180度,有效的纬度为-85.05112878度到85.05112878度,超出指定范围时,返回一个错误;已经添加的数据无法再次添加geopos <key> <member> [member...]:获得member的坐标值geodist <key> <member1> <member2> [m|km|ft|mi]:获取两个位置之间的直线距离,单位:m为米(默认),km为千米,mi为英里,ft为英尺georadius <key> <longitude> <latitude> radius m|km|ft|mi:以给定经纬度为中心,输出某一半径内的元素
配置文件redis.conf
Units(单位)
文件开头定义了一些基本的单位换算,支持bytes,不支持bit
1
2
3
4
5
6
7
8
9
10
11# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
INCLUDES(包含)
1 | # Include one or more other config files here. This is useful if you |
- 多实例的情况,把公用的配置文件提取出来,作为include的内容
网络相关配置
1 | bind 127.0.0.1 |
bind
- 默认情况bind=127.0.0.1,只接受本机的访问请求
- 不写的情况下,无限制接受任何ip地址的访问
- 生产环境中为应用服务器的地址
- 开启protected-mode,则没有设定bind ip且没有设密码的情况下,只接受本机的响应
protected-mode
- 为yes时,只能本机访问
port
- 端口号,默认6379
tcp-backlog
- 设置tcp的backlog
- backlog是一个连接队列,队列长度总和=未完成三次握手队列 + 已经完成三次握手队列
- 高并发环境下需要一个高backlog值,避免慢客户端连接问题
- Linux内核会将该值减小到
/proc/sys/net/core/somaxconn(128),需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)
timeout
- 空闲的客户端维持多少秒会关闭,0表示关闭该功能,永不关闭
tcp-keepalive
- 对访问客户端的心跳检测,每n秒检测一次,如果没有alive则server释放连接,如果为0,则不进行Keepalive检测
GENERAL(通用)
daemonize
- 是否后台启动(类似于
nohup &)
pidfile
- 存放pid文件的位置,默认会把pid(进程号)写入
/var/run/redis.pid文件
loglevel
- 指定日志记录级别
- 支持四个级别:debug、verbose、notice、warning,默认为notice
- 生产环境选择notice或warning
logfile
- 日志文件名称
databases
- 库的数量
SECURITY(安全)
设置密码
requirepass 123456可以命令行中设置密码,但如果重启redis,密码会被还原
1
2
3config get requirepass
config set requirepass "123456"
auth 123456
LIMITS(限制)
maxclients
- redis同时可以与多少个客户端进行连接,默认为10000
- 达到限制,会拒绝新的连接请求,返回“max number of clients reached”
maxmemory
- redis可以使用的内存量,到达使用上限后会根据maxmemory-policy尝试移除数据
- 如果无法移除,或者设置“不允许移除”,redis则对需要申请内存的指令返回错误信息,但仍然正常响应不申请内存的指令,如GET
- 如果redis是主redis,设置内存使用上限时需要留出内存空间给同步队列缓存
maxmemory-policy
volatile-lru:对过期的key使用LRU算法移除(最近最少使用)
allkeys-lru:对所有的key使用LRU算法移除
volatile-random:移除随机的过期key
allkeys-random:移除随机的key
volatile-ttl:移除TTL值最小的key,即最近要过期的key
noeviction:不进行移除
maxmemory-samples
- 设置样本数量,redis默认会检查这么多个key并选择其中LRU的那个删除
- 一般设置3到7,数值越小越不准确,但性能消耗越小
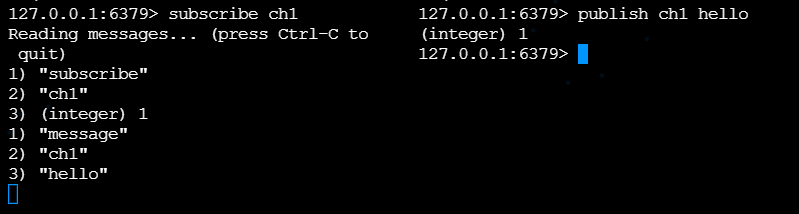
发布和订阅
一种消息通信方式,pub(发送者)发送消息,sub(订阅者)接收消息
客户端订阅频道(channel)
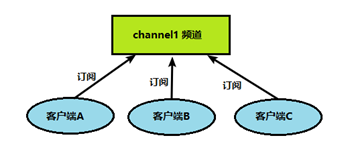
向频道发布消息后,消息发给订阅的客户端(如果客户端订阅了channel2,但消息只向channel1发布,则客户端无法收到该消息)
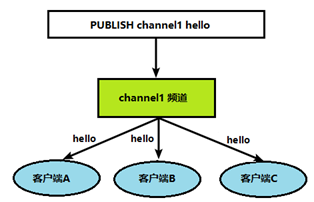
命令行实现(客户端A和客户端B):A订阅ch1,B通过ch1发布hello