TDDL 分布式数据库中间件
分布式数据库
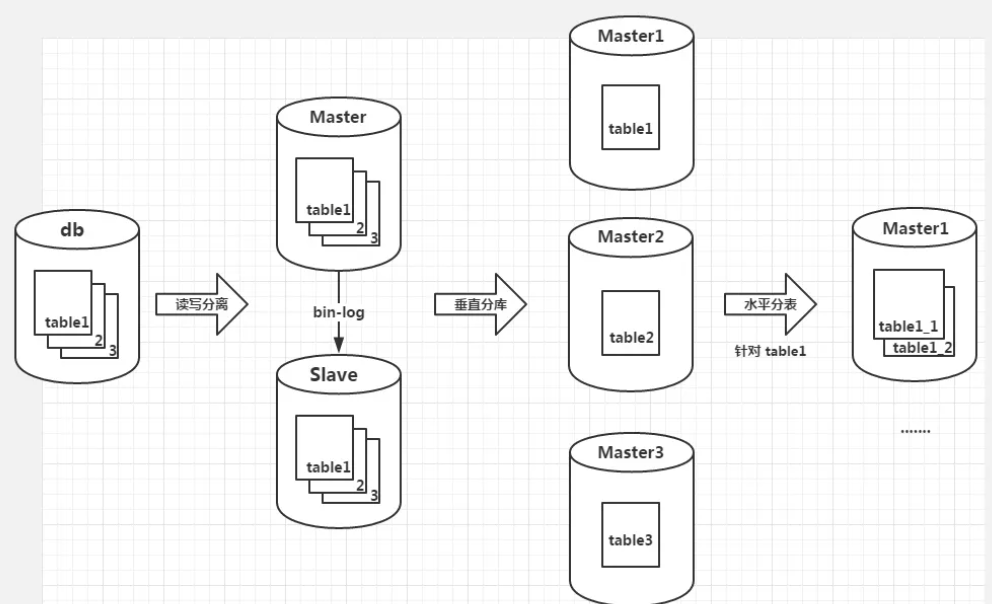
- 单库单表:数据库中的业务表是一张对应业务的完整的表
- 读写分离:数据库 Master 的基础上增加一个备用数据库 Slave,备库只提供读服务,不提供写服务
- 数据复制问题:短期的数据不一致性,没有什么特别好的办法,主要依赖于数据库提供的数据复制机制(主从复制)
- 数据源选择问题:程序中应该根据 SQL 来判断出是读操作还是写操作,进而选择要访问的数据库
- 垂直分库:根据业务特点考虑将数据库垂直拆分,把数据库中不同的业务单元的数据划分到不同的数据库里面
- ACID 被打破:数据分到不同的数据库之后,原来的事务操作将会受很大影响。例如,注册账户的时候需要在用户表和用户信息表中插入一条数据,多机情况下会变得比较麻烦
- Join 操作困难
- 外键约束受影响
- 水平分表:把一张表内大量的数据拆分成多张子表——会在垂直分库的基础上带来更多的影响
- 自增主键会有影响:不能产生唯一的 ID 了,因为逻辑上来说多个分表其实都属于一张表,自增主键无法标识每一条数据
- 有些单表查询会变成多表:例如count操作,从多张分表中共同查询才能得到结果
TDDL
作用:
- 系统容灾
- 运维管理—— 直接连接单机数据库时,无法动态的切换数据源
- 单一数据库无法满足性能要求
模型:
 * 主要部署在ibatis、mybatis或者其他ORM框架之下,JDBC Driver之上
* 可以将Tddl当做普通数据源实例并且注入到各种ORM框架中使用
* 主要部署在ibatis、mybatis或者其他ORM框架之下,JDBC Driver之上
* 可以将Tddl当做普通数据源实例并且注入到各种ORM框架中使用
分布式数据库物理结构
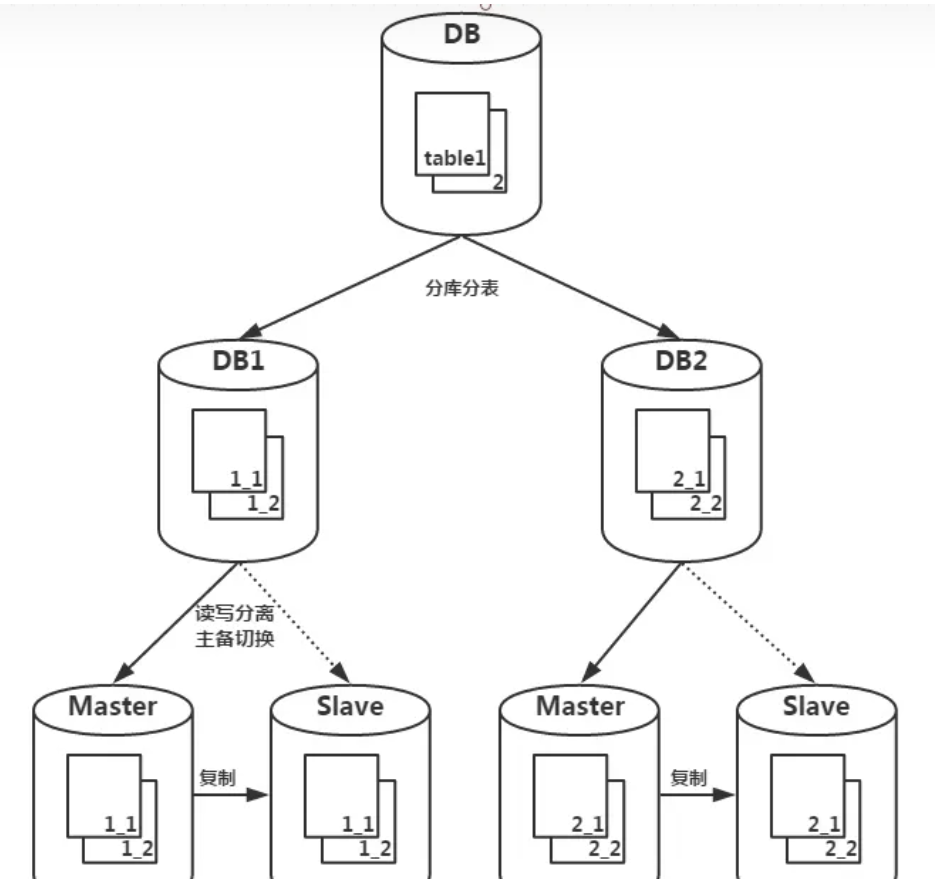 * 为了解决每一层所要应对的问题,tddl自上而下也分了三层,分别是 Matrix 层、Group层以及 Atom 层
* 最顶层要进行分库分表,因此分库分表所带来的问题是在 Matrix 层解决,包括SQL解释、优化和执行
* 中间层要进行读写分离和主备切换,因此由 Group 层解决
* Atom 面对的是实实在在数据库,需要管理对数据库的连接,比如当数据库的 IP 地址发生改变时,Atom 层要动态感知,以免连接找不到地址
* 为了解决每一层所要应对的问题,tddl自上而下也分了三层,分别是 Matrix 层、Group层以及 Atom 层
* 最顶层要进行分库分表,因此分库分表所带来的问题是在 Matrix 层解决,包括SQL解释、优化和执行
* 中间层要进行读写分离和主备切换,因此由 Group 层解决
* Atom 面对的是实实在在数据库,需要管理对数据库的连接,比如当数据库的 IP 地址发生改变时,Atom 层要动态感知,以免连接找不到地址
三层结构:
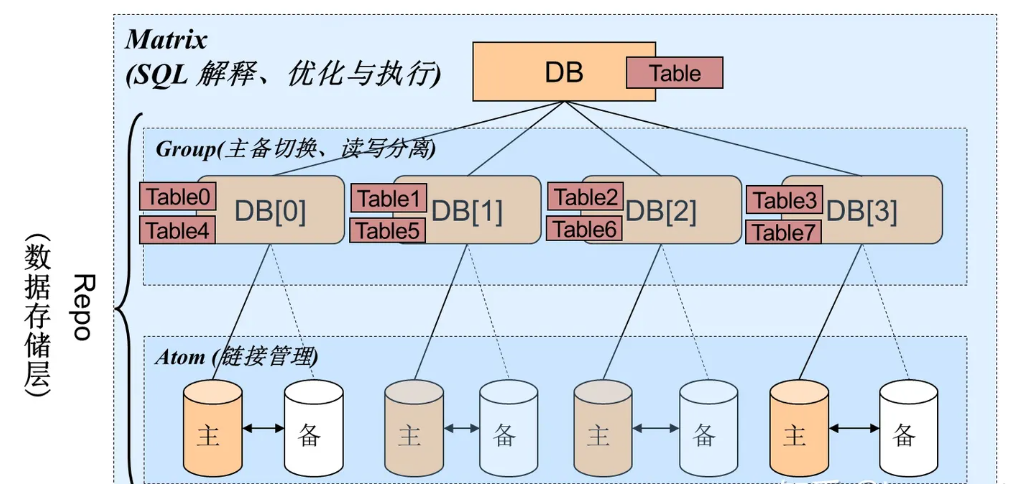 * TDDL作为中间件,根据路由规则,将sql路由到正确的分库、分表上去执行,再将结果进行汇总,返回给用户。用户不需要了解TDDL的原理,可以像使用单库单表一样去使用分布式数据库
* TDDL作为中间件,根据路由规则,将sql路由到正确的分库、分表上去执行,再将结果进行汇总,返回给用户。用户不需要了解TDDL的原理,可以像使用单库单表一样去使用分布式数据库
Matrix层
分库分表路由,SQL语句的解释、优化和执行,事务的管理规则的管理,各个子表查询出来结果集的Merge等
数据访问路由算法: 规定了数据的存储位置,同样也由它来指明该去哪里查询数据
固定哈希算法——根据某个字段对分库的数量或者分表的数量进行取模
- 基本能保证数据均匀分布
- TDDL 的默认路由算法
- 数据迁移的成本高,增加数据库时大多数数据需要迁移
一致性哈希算法:
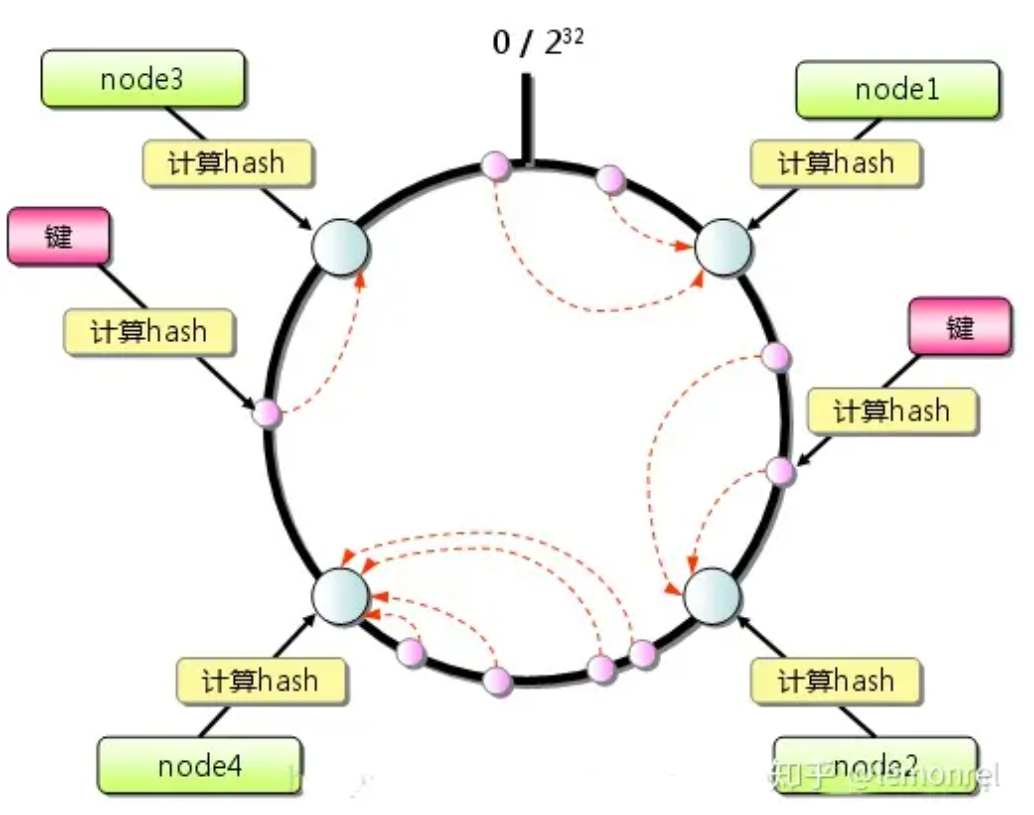
- 计算出 key 的 hashcode 之后对 2^32 取模,放到最近的机器上(机器的唯一标识同样取模)
- node2 与 node4 之间增加一台机器 node5,需要迁移的数据只分布在 node2 与 node5 之间
虚拟节点:解决”数据集中在某一热点“的问题
- 一个物理节点复制出多个虚拟节点,均匀分布在环上,那么即使数据再集中,其实也会存储在不同的节点上
自定义路由规则
Group层
- 作用:
- 数据库读写分离,基本上主数据库负责读写,备份数据库只负责读;主备切换状态对调后备库变为主库,主库变为备库
- 数据保护:数据库挂掉后的线程保护
- 权重选择:根据权重去读某些库
- 读写分离时的数据复制
- 镜像复制:主库和从库的数据结构一模一样的,根据主库上的日志变化,在从库中执行相同的操作
- 非对称复制:主库与备库以不同的方式分库,结构虽然相同,但是主备库中存储的记录是不相同的——查询条件不同时,把请求分发到更加适合的库去操作
- 对于订单数据库,买家会根据自己的 ID 去查自己的交易记录,主库可以用买家 ID 分库,保证单个买家的记录在同一个数据库中
- 卖家如果想看交易记录可能得从多个库中查询,这时候利用卖家 ID 进行分库作为备库,此时主备库的复制不能简单的镜像复制,进行复制操作之前还需要进行路由
- 作用:
Atom层
- 和物理数据库交互,提供数据库配置动态修改能力
- 负责动态创建,添加,减少数据源
- 底层对物理数据库做了代理,对单库的JDBC做了一层封装,执行底层单库的SQL
执行流程
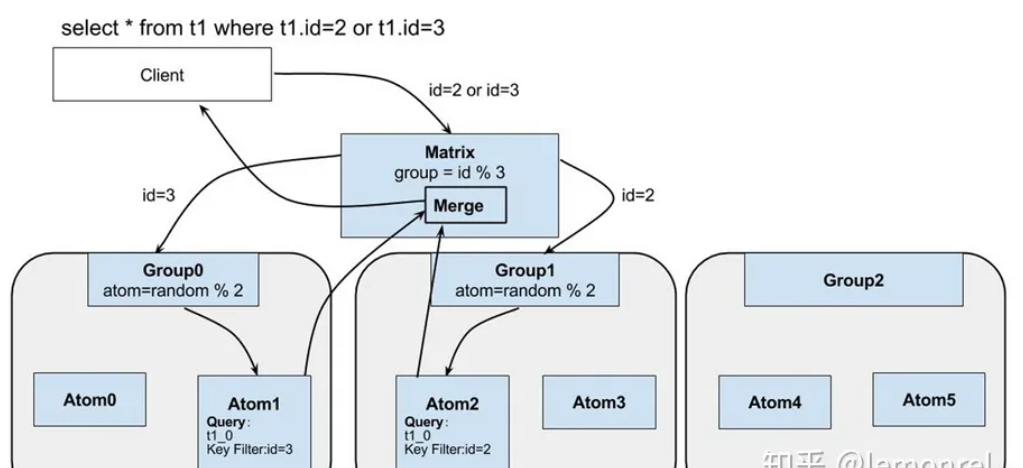 * client发送一条SQL的执行语句,会优先传递给Matrix层。由Martix 解释 SQL语句,优化,并根据查询条件路由到各个group,转发sql进行查询;各个group根据权重选择其中一个Atom进行查询,各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client
* client发送一条SQL的执行语句,会优先传递给Matrix层。由Martix 解释 SQL语句,优化,并根据查询条件路由到各个group,转发sql进行查询;各个group根据权重选择其中一个Atom进行查询,各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client
Matrix层
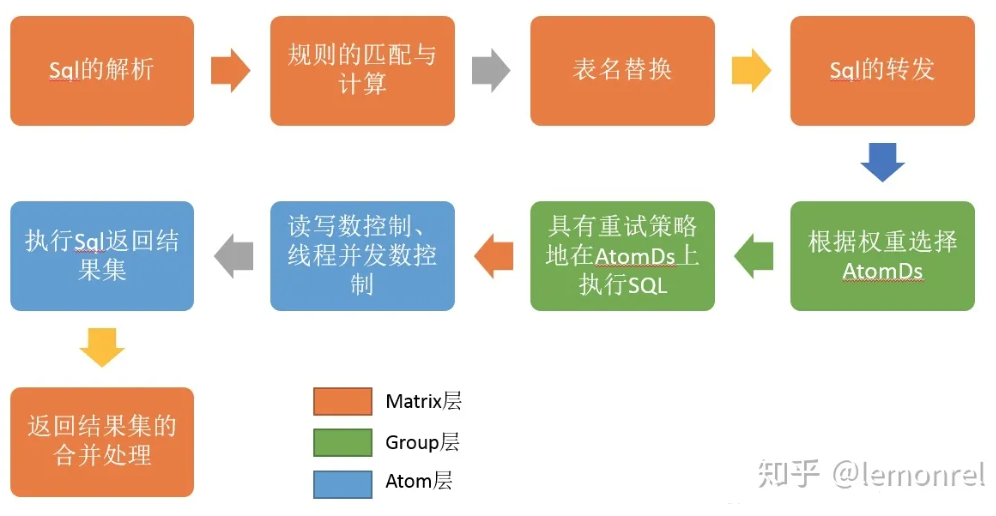
- Sql的解析。将Sql语句解析成一颗抽象语法树(Abstract Syntax Tree),解析一个好处理的结构
- 规则的匹配与计算。基于上一步创建的语法树查找匹配的规则,根据规则去确定分库分表的结果
- 规则可以简单的看做是定义数据库怎么进行分库分表,要分成几张库几张表,库名和表名的命名是怎么样的。规则的匹配就是根据SQL的语句确定,具体查询的子表是哪几张
- 表名替换。对于开发人员来说,它查询的表直接就是select * from A.B limit 10(A为数据库名,B为数据表名)。但底层会把这些表名替换成类似select * from A_000.B_001,select * from A_000.B_002,select * from A_001.TABLE_001的形式。表名替换把总表的名称替换为这些子表
- Sql的转发。将生成的各个sql语句转发到对应的Group进行执行。以上例,转发给Group0的查询为where id=3,转发给group1的查询为where id =2——查询的条件会发生一定修改
- 综上,对原始的Sql进行分解,将原本单库单表的查询语句,转发到多库多表并行执行,提高了数据库读写的性能
Group层
- 根据权重选择AtomDs。通常会在主节点和副节点上读取数据,只在主节点上写入数据
- 具有重试的策略地在AtomDs上执行SQL。防止单个的AtomDs发生故障,以确保尽可能多的数据访问可以在正常数据库中访问
Atom层
- 读写数控制、线程并发数控制
- 执行sql,返回结果集。Atom底层利用druid管理连接池,具体查询还对JDBC做了封装。执行完Sql后结果返回给Matrix
全局唯一id
- 基于tddl进行分库分表后,原本一个数据库上的自增id的结果,在分库分表下并不是全局唯一的。所以,分库分表后需要有一种技术可以生成全局的唯一id
- 方案:
- oracle sequence:基于第三方oracle的SEQ.NEXTVAL来获取一个ID
- 简单可用
- 需要依赖第三方数据库oracle
- mysql ID区间隔离:不同分库设置不同的起始值和步长,比如2台mysql,就可以设置一台只生成奇数,另一台生成偶数;或者1台用0
10亿,另一台用1020亿.。- 利用mysql自增id
- 运维成本比较高,数据扩容时需要重新设置步长
- 基于数据库更新+内存分配:在数据库中维护一个ID,获取下一个ID时,会对数据库进行ID=ID+100 WHERE ID=XX,拿到100个ID后,在内存中进行分配
- 简单高效
- 无法保证自增顺序
- oracle sequence:基于第三方oracle的SEQ.NEXTVAL来获取一个ID
- tddl基于方案三
- 只要生成id的数据库不全部挂掉,均可以顺畅提供服务
- 生成id的数据库数量不定,按照应用对容灾的需求指定不同机架不同机房的数据库
- 举例:
- sample_group_0-sample_group_3是我们生成全局唯一id的4个数据库,每个数据库对于同一个id有一个起始值,比如间隔是1000
- 应用真正启动的时候,可能某一台机器上去取id,随机取到了sample_group_1,那么这台机器上的应用会拿到1000-1999这一千个id,下次从sample_group_1上取得的id变成4000-4999—— sample_group_1会永远只会取到1000-1999,4000-4999,8000-8999,12000-12999等

